
本项目的构思起源于学校的选课系统。每逢选课期间,学校的网站就会变得非常卡。这时候选课会变得极其困难,一个网页从请求到响应的时间最长在半个小时左右,这样长时间的等待会使人极其不耐烦。导致很多同学都无法安心的完成选课。这时候会有很多“选课高手”,他们有所谓的“选课技巧”可以快速完成选课。
渐渐的,“选课”这个词演变成为“抢课”。此时抢课也成为了一个“小商机”。根据我的了解,绝大多数帮忙选课的同学都是手动完成的,这就意味着他们需要花费大量的时间在页面等待这方面,同时也意味着“帮忙”的数量会受到浏览器多开窗口个数的限制。随着浏览器多开窗口的增多,出错率也会增加。例如某个窗口对应的同学需要选择课程A,但是由于人类的粗心大意,将课程选择成了课程B……
这时我在想:“为什么不开发出一个脚本,可以帮助我完成选课呢?”——最早起源于作者大一上学期(2022年)。
为此本项目应运而生。
- 2023 年 10 月 24 日:项目开发启动。
- 2023 年 12 月 25 日:小数量测试,验证核心功能可行性。
- 2024 年 3 月 27 日:核心功能基本开发完毕。
- 2024 年 4 月 22 日:第一次真实环境测试。
- 2024 年 4 月 23 日 —— 2024 年 6 月 28 日:二次开发阶段。
- 2024 年 6 月 29 日:第二次真实环境测试并按计划完成所有选课任务。
- 2024 年 8 月 28 日 —— 2024 年 9 月 28 日:核心功能代码重构、基本服务开发等等。
- 后端:
FastAPI、MongoDB、Redis、基于 Redis 实现的消息队列、asyncio、aiohttp。 - 前端:
Vue3、Element-Plus。 - 部署方案:云服务器(前端) + 通过
zerotier创建一个局域网环境与前端通信(后端)。
- 易于用户操作的可视化界面(这是绝大多数抢课系统不具备的)。
- 利用 爬虫 技术向选课接口发送请求,加快选课速度。
- 使用基于
Redis实现的延时任务队列,支持提前提交选课任务,自动判断是否到达选课时间。 - 利用 消息队列 实现 多任务 + 定时 爬虫任务。
- 后台使用
Redis发布订阅 和WebSocket全双工通信 实现对选课任务的实时监控。 - 使用 缓存 对选课参数进行 复用,更进一步地加快了选课速度。
- 选课接口集成
Google人机验证。 - 通过
腾讯云服务发送选课成功邮件。 - 支持用户查询选课进度。
- 前端显示课程的已选择人数。
- 不提供密码也能完成选课。
-

-

在这里简单描述一下:
- 在选课 API 被调用之前,系统会提前挂起一个的任务队列进程,该进程用于监听选课 API 提交的任务。
- 在 API 被调用之后,
Arq-Worker会监听到有任务被提交,于是将任务从队列中取出。 - 当任务被取出之后,假如任务类型是
select_course,那么首先会检查Redis中是否包含用户对应的会话。如果没有,系统会主动地去保存会话(如果会话设置失败,任务会直接结束)。接着获取选课的时间,最后将选课任务再次发送到任务队列。 - 当到达任务设定的时间之后,
Arq-Worker会不断的从任务队列中取出并执行任务。 - 当任务被执行后,调用相应的课程选择器来进行选课操作,期间任意一个关键步骤失败都会记录失败信息,失败后会重试。当到达最大重试次数后(这里设置的是 3 次),直接判定选课失败。
- 最后整个任务执行完毕。
-
课程选择器的本质其实就是一个爬虫程序,只不过就是经过反复抽象,最终成为了一个可扩展性非常强的课程选择器类。
在
/snatcher/selector/base.py下,定义了一个名为BaseCourseSelector的类,它是所有课程选择器类的父类。在这个类中定义了一个课程选择器应有的属性的抽象方法。这个类派又生出一个类:
AsyncCourseSelector,异步课程选择器类。这个类所处的文件目录为:
/snatcher/selector/async_selector.py。它表示所有发送请求使用的库都是aiohttp。所有代码逻辑都是异步非阻塞的。它定义了一个异步选择器类的通用方法,接着它又派生出了两个重要的类:
AsyncPCSelector:公选课选择器类,专门用于实现公选课选课逻辑。AsyncPESelector:体育课选择器类,专门用于实现体育课选课逻辑。
下图是它们之间的继承关系:
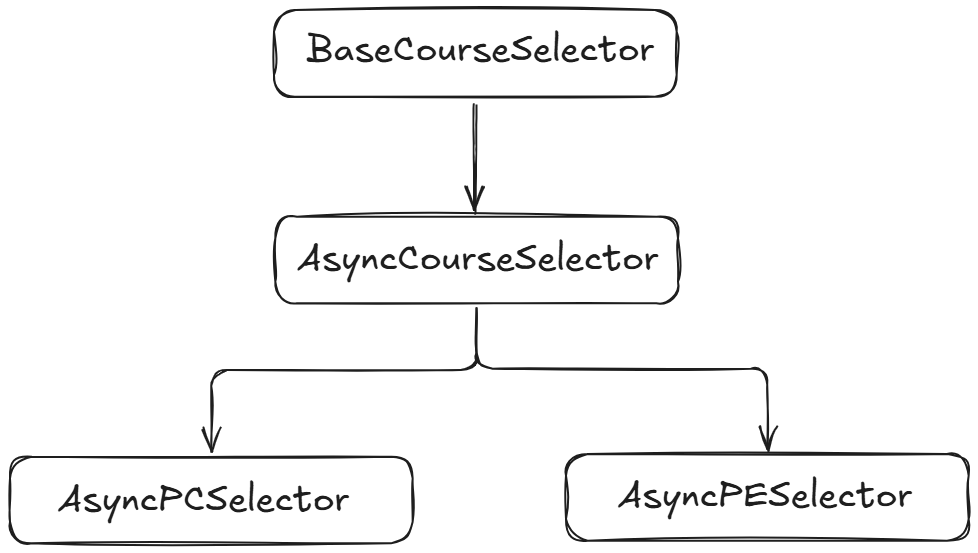
-
整个日志的创建与监听都是围绕
Redis的发布-订阅模型展开的。
-
所谓“解耦”,就是低耦合。表示每个模块或者功能之间没有太多的依赖关系,每个模块或者功能单独拿出来也能够正常使用,提高了模块或者功能的可复用性。
例如本项目中的课程选择器,单独拿出来也是可以使用的;还有
snatcher整个包,不需要依赖前端的调用,手动调用也完全可以实现对应的功能,它提供了一个统一的对外接口,以至于让所有的 Python 程序都能够轻松的调用它。其实
snatcher可以完全脱离前端和后端使用,只不过为了让这个系统对外部调用者显得更加友好,所以最终决定以Web 的形式呈现到用户的眼中,同时也提高了整个系统的安全性。




在项目的根目录下,包含以下几个重要的文件或文件夹:
backend:后端模块,主要负责向外部提供接口。接口包括课程模块和后台管理模块。frontend:前端模块,负责为用户提供一个可视化界面,以用于选课。manager:后台管理模块,对整个系统的数据和日志有一个上帝视角。snatcher:系统核心模块,所有选课逻辑位于该目录下(说明文档要点进去才有)。logs:记录每次选课的日志信息。mongodb:数据库连接配置文件。requirements.txt:系统运行所需的第三方库。
在部署方面,可能是这个项目最致命的缺点,在这里我详细的分析一下:
首先选课这个操作是必须要在校园网下进行的,也就是说当前网络是一个局域网。只有当前设备的网络环境处于校园网下,才能正常进行选课操作(当然,如果你是老师,有将会专属的 VPN 来访问校园网)。
所以整个发送请求的过程,都必须在本地进行,不能在云服务器上。因为云服务器的网络不是校园网,它是不能访问本地局域网的。当然,我也有想过让云服务器与本地局域网之间实现数据互通,但最终还是做不到……
因此刚开始我想的是把整个项目都部署在本地,通过内网穿透的形式将服务映射到外网,这种方式是行得通的。但是这样做会有一个弊端,由于内网穿透是通过端口映射的,也就是说只有当前端处于运行的状态下,才会暴露出一个端口,但是前端直接运行的代码是没有经过编译的,每一次网络传输都要传输大量的未经编译的数据,这样做的结果只有一个,那就是传输效率低,传输速度慢。这里是经过了实践的,将一个普通的Vue3应用映射出去,客户端的渲染时间达到了十几秒。
传输速度过慢以及客户端渲染的时间较长,可能是因为未编译过的前端文件过多再加上内网穿透的传输速度较慢,导致了客户端渲染的时间过长。
因此我最终决定__将前端打包放在云服务上,将后端的服务通过内网穿透映射出去__。在这里前后端都是使用JSON来进行交互的,而JSON本身是个轻量级数据,所以传输速度得到了一个很大的提升。加上前端本身是已经编译好的,所以客户端渲染的速度也非常快。
所以项目最终的部署方案是:将前端打包独自放在云服务器上,而其他所有资源都部署在本地。
这样部署的缺点就是只有当本地服务启动的时候,外部才能使用正常的服务。而本地服务是不能过长时间启动的,因为电脑总要关机嘛。所以我在开头的时候说部署是这个项目最致命的缺点就是这个意思。
注意,我这里所说的快速上手指的是如何使用内部工具完成选课,而不是启动整个项目。这个工具不包括前端、后端、消息队列、数据库等服务,并且只适用于个人选课。
首先,你需要提前准备好这些东西:
- 意向课程名字(这个可以随便取名字)
- 意向课程对应的课程号 ID(kch_id)
- 意向课程对应的教学班 ID(jxb_id)
上述参数都可以在教务系统中拿到,可以自己研究一下。
准备好了嘛?那就开始吧!😊
Redis:确保你的电脑已经安装了Redis,并且版本建议在 5.0 以上。它在项目中发挥了至关重要的作用。Python:安装Python环境,项目所依赖的Python版本必须 大于等于Python 3.10。
-
将项目的主支从
GitHub中下载到本地。git clone https://github.com/thcpdd/snatcher.git -b master
-
进入项目根目录
cd ./snatcher -
创建并激活虚拟环境
python -m venv ./venv # 创建虚拟环境 # 激活虚拟环境 .\venv\Scripts\activate # Windows系统 source ./venv/bin/activate # Linux系统
-
安装项目所需依赖
pip install -r requirements.txt
-
更改项目配置信息
首先打开
./snatcher/conf.py文件。在文件中你会看到
Settings这个类,里面的类属性是整个项目的所有配置信息。你现在需要留意以下 3 个配置:
- TERM:选课学期,整数类型。上学期填 3,下学期填 12。
- SELECT_COURSE_YEAR:选课学年,整数类型。无论是上学期还是下学期,都填写上学期的年份。例如,假设选课时间是 2025 年 4 月份,要填的就是上学期的年份 2024;假如选课时间是 2024 年 10 月份,那么当前学期就是上学期,直接填 2024 就行了。
- START_TIME:开始选课的时间,字典类型。按照键的名字来填就行了。
注意,请务必将上述信息完全填写正确,否则将会影响选课。
项目内部向外提供了一个及其简单的调用方式。
首先,在项目的根目录下创建一个 Python 文件并写入以下内容:
from snatcher.selector import SimpleSelectorPerformer, AsyncPESelector
goals = [
('足球俱乐部1', '1BB2143990AF721DE0630284030A2394', '1B4A6FAFDEC4AEF0E0630284030AD355'),
('散打俱乐部', '1C661CABC37FA592E0630284030A735A', '1B398450EB7C2B44E0630284030A0D78')
]
username = '你的学号'
password = '你的密码'
performer = SimpleSelectorPerformer(username, password, AsyncPESelector, goals)
performer.perform()这段代码描述了一个体育课选课的基本调用过程,下面是对每一行代码或变量的解释:
- 第一行导包:导入项目内部的工具,这里就不多解释了。
- SimpleSelectorPerformer:简单课程选择器执行器,它封装了一个课程选择器调用的基本方式,并且内部自带日志输出,你可以理解为它是一个“迷你智能抢课系统”。
- AsyncPESelector:异步体育课选择器,整个类封装了完整的体育课选课逻辑。如果是公选课,那么你需要将类名中的 “E” 改为 “C” 即可。
- goals:你的意向课程列表,每一个列表元素都是一个由 (课程名字、课程号ID、教学班ID) 构成的三元组。课程选择器会按顺序的尝试选择每一个课程,假如第一个课程失败了,那么它会尝试后面的课程,直到列表遍历完毕……
- username:你的学号。
- password:你的密码。
- performer:执行器的实例化对象。注意,传入的
AsyncPESelector课程选择器不需要加括号❗并且不要尝试手动调用课程选择器❗除非你对其内部原理足够了解。 - performer.perform():调用内部方法并执行选课逻辑。
执行上述代码会发生什么?
- 自动模拟登录并保存登录状态。
- 自动执行选课逻辑。
- 期间会连接
Redis并不断输出日志信息。
确保输入参数正确并在选课开始时运行这个 Python 文件,你将会看到类似于以下的内容:

整个过程仅仅花费了一秒钟左右的时间。当然,在选课期间日志的输出并不会这么频繁。也有可能会输出别的信息,比如重试、异常等等……但这些都不需要你自己处理,系统内部会自动帮你处理这些问题。
在上面提到执行了上述代码会自动模拟登录,但模拟登录的过程可以在选课之前完成。例如,在一个 Python 文件中写入以下内容:
import asyncio
from snatcher.session import async_check_and_set_session
async def main():
username = '你的学号' # 请用真实信息替换它
password = '你的密码' # 请用真实信息替换它
await async_check_and_set_session(username, password)
asyncio.run(main())运行上述代码,系统内部会自动帮你提前登录好并保存登录状态(请确保提前登录的时间和选课的时间在同一天)。这样在调用选课逻辑的时候可以跳过登录步骤,直接进入到选课阶段,进而大大提高选课的速度。
以上就是快速上手项目的所有内容了,如果你想启动整个项目,你可能需要花不少时间把整个项目吃透,才有可能将每个组件成功启动。
关于项目更详细的介绍,可以参考:https://docs.thcpdd.com/#/snatcher/introduce