LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models
Long Lian, Boyi Li, Adam Yala, Trevor Darrell at UC Berkeley/UCSF.
Paper | Project Page | 5-minute Blog Post | HuggingFace Demo (stage 1 and 2) | Citation
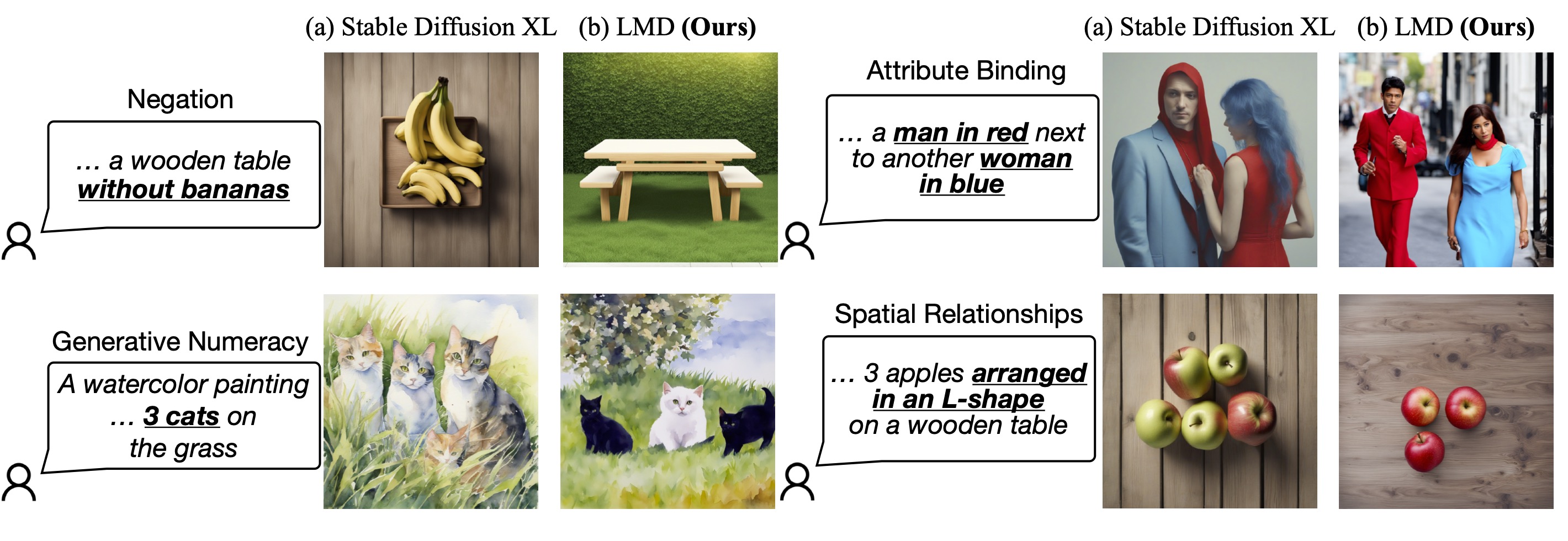
TL;DR: Text Prompt -> LLM as a request parser -> Intermediate Representation (such as an image layout) -> Stable Diffusion -> Image.
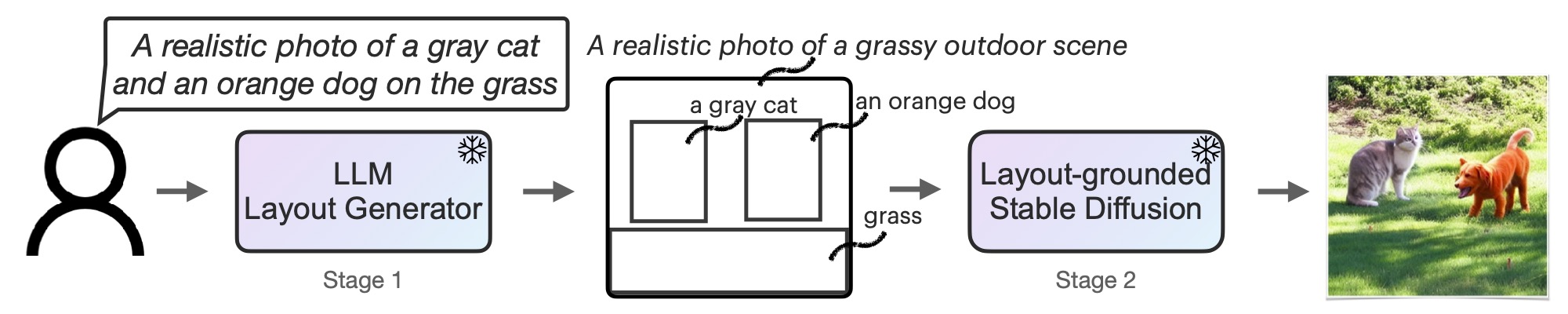
Our huggingface demo for stage 1 and 2 is released! Check it out here.
Our code (stage 1 and stage 2) is also available to run locally. The code and instructions to run.
Our code that supports text-to-layout (stage 1) and layout-to-image (stage 2) generation is released. Click here to see the code and instructions to run.


Please contact Long (Tony) Lian if you have any questions: [email protected].
If you use this work or find it helpful, please consider giving a citation.
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}