流批一体数据交换引擎
实现从源读取数据 -> (目标数据类型转换 | 数据分发) -> 写到目标数据源
支持数据流传输过程中进行融合计算查询
支持CDC模式增量同步方案
- 产品由etl-engine引擎和etl-designer云端设计器及etl-crontab调度组成,
- etl-engine引擎负责解析etl配置文件并执行etl任务,
- etl-designer云端设计器通过拖拉拽的方式生成etl-engine引擎可识别的etl任务配置文件,
- etl-crontab调度设计器负责按时间周期执行指定的etl任务,etl-crontab调度还提供了查询etl任务执行日志功能,
- 三部分组成了etl解决方案,可集成到任意使用场景。
-
etl-engine下载地址
当前版本最后编译时间20240728 -
etl-designer设计器视频播放地址
etl-designer设计器支持OEM发行(目前已经集成到etl_crontab中使用) -
etl-crontab调度设计器视频播放地址
-
etl-engine配置文件样例
-
etl-engine嵌入go脚本视频播放地址
- 支持跨平台执行(windows,linux),只需要一个可执行文件和一个配置文件就可以运行,无需其它依赖,轻量级引擎。
- 输入输出数据源支持influxdb v1、clickhouse、prometheus、elasticsearch、hadoop(hive,hbase)、postgresql(兼容Greenplum))、mysql(兼容Doirs和OceanBase)、oracle、sqlserver、sqlite、rocketmq、kafka、redis、excel
- 任意一个输入节点可以同任意一个输出节点进行组合,遵循pipeline模型。
- 支持跨多种类型数据库之间进行数据融合查询。
- 支持消息流数据传输过程中与多种类型数据库之间的数据融合计算查询。
- 数据融合查询语法遵循ANSI SQL标准。
- 为满足业务场景需要,支持配置文件中使用全局变量,实现动态更新配置文件功能。
- 任意一个输出节点都可以嵌入go语言脚本并进行解析,实现对输出数据流的格式转换功能。
- 支持节点级二次开发,通过配置自定义节点,并在自定义节点中配置go语言脚本,可扩展实现各种功能操作。
- 任意一个输入节点都可以通过组合数据流拷贝节点,实现从一个输入同时分支到多个输出的场景。
- 支持将各节点执行日志输出到数据库中。
- 支持跟crontab调度组合配置,实现周期性执行etl-engine任务。
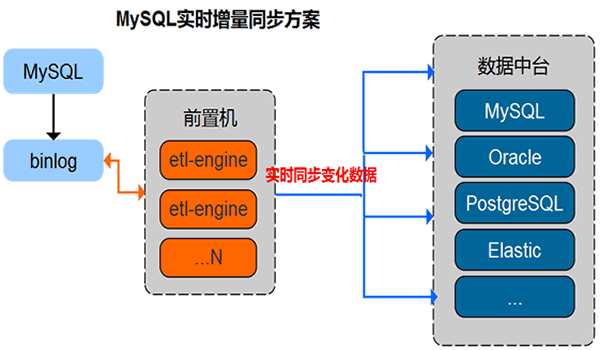
- 支持MySQL CDC模式数据同步,将MySQL数据库表数据的变化实时同步到其它MySQL、Oracle、PostgreSQL、Elastic等数据库.
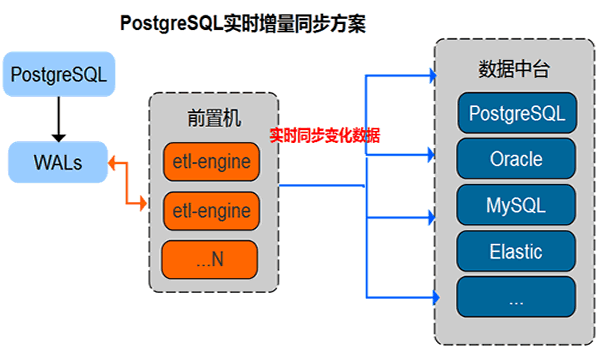
- 支持PostgreSQL CDC模式数据同步,将PostgreSQL数据库表数据的变化实时同步到其它MySQL、Oracle、PostgreSQL、Elastic等数据库.
- 输入输出任意组合
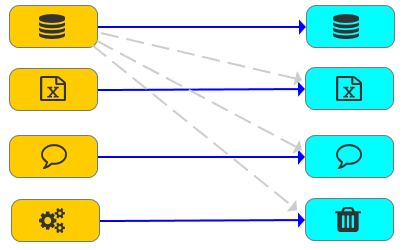
- 输出节点嵌入Go语言 方便格式转换

- 数据流复制 方便多路输出

- 自定义节点嵌入Go语言 方便实现各种操作

- 转换节点嵌入Go语言 方便实现各种转换
-
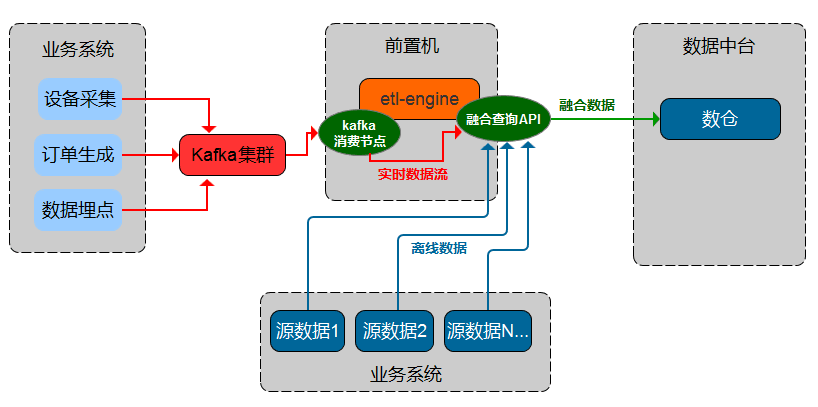
流批一体融合查询
支持多源输入,内存计算,融合输出 融合查询语法
-
MySQL CDC模式数据同步
支持将Master MySQL数据库数据实时同步到其它MySQL、Oracle、PostgreSQL、Elastic等数据库
提供数据实时同步备份、增量对比能力视频播放地址
- PostgreSQL CDC模式数据同步
支持将Master PostgreSQL数据库数据实时同步到其它PostgreSQL、MySQL、Oracle、Elastic等数据库
提供数据实时同步备份、增量对比能力视频播放地址
- etl_crontab与etl_engine灵活组合
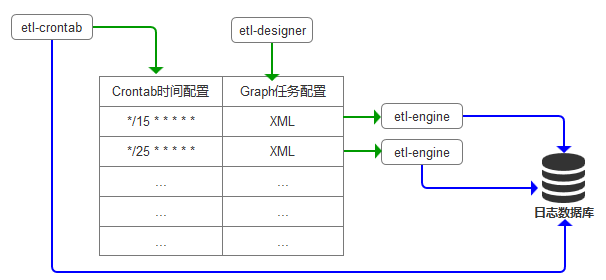
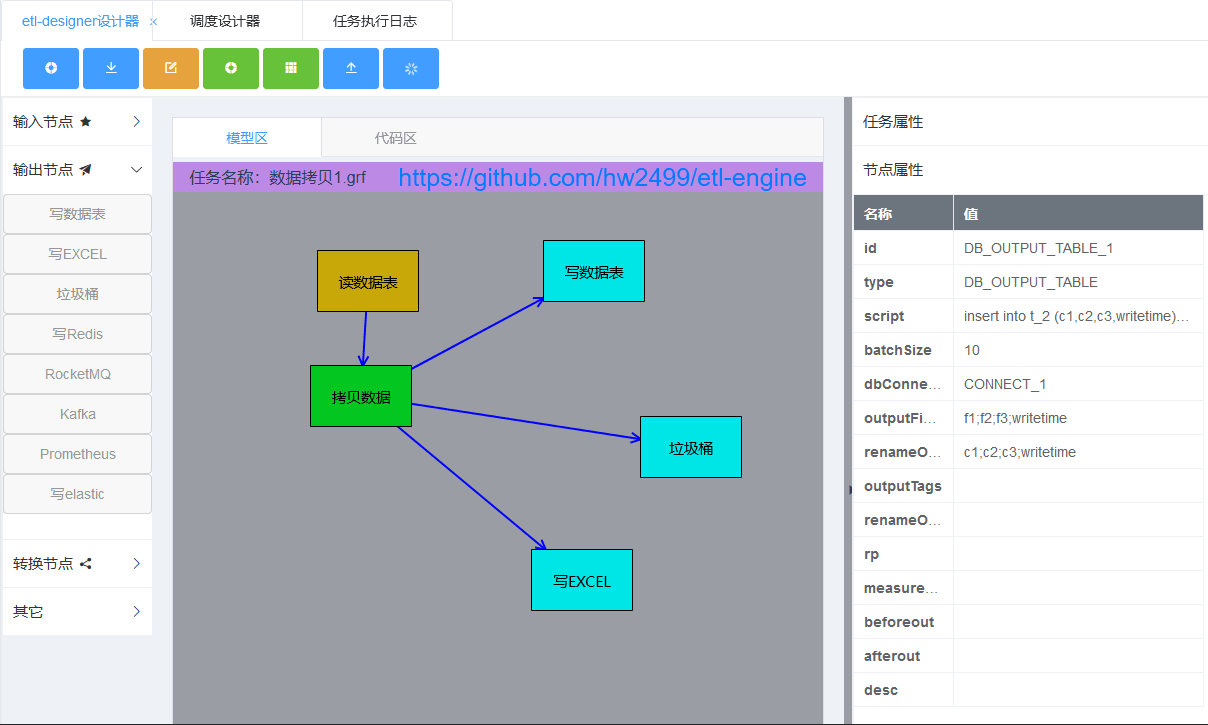
- etl-designer设计器
- 调度设计器

- 调度日志
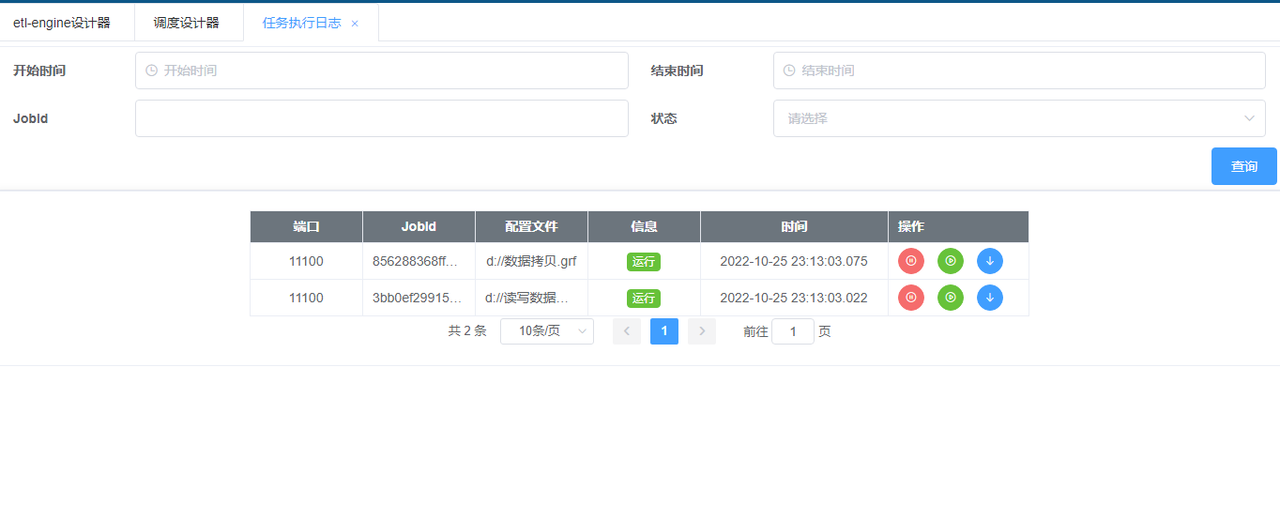
- Etl日志明细

etl_engine.exe -fileUrl .\graph.xml -logLevel info
etl_engine -fileUrl .\graph.xml -logLevel info
<?xml version="1.0" encoding="UTF-8"?>
<Graph>
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="5">
<Script name="sqlScript"><![CDATA[
select * from (select * from t3 limit 10)
]]></Script>
</Node>
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="节点2" dbConnection="CONNECT_02" outputFields="f1;f2" renameOutputFields="c1;c2" outputTags="tag1;tag4" renameOutputTags="tag_1;tag_4" measurement="t1" rp="autogen">
</Node>
<!--
<Node id="DB_OUTPUT_02" type="DB_OUTPUT_TABLE" desc="节点3" dbConnection="CONNECT_03" outputFields="f1;f2;f3" renameOutputFields="c1;c2;c3" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t1 (c1,c2,c3) values (?,?,?)
]]></Script>
</Node>
-->
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="DB_OUTPUT_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="c1" type="string" default="-1" nullable="false"/>
<Field name="c2" type="int" default="-1" nullable="false"/>
<Field name="tag_1" type="string" default="-1" nullable="false"/>
<Field name="tag_4" type="string" default="-1" nullable="false"/>
</Metadata>
<Connection id="CONNECT_01" dbURL="http://127.0.0.1:58080" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<Connection id="CONNECT_02" dbURL="http://127.0.0.1:58086" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<!-- <Connection id="CONNECT_04" dbURL="127.0.0.1:19000" database="db1" username="user1" password="******" type="CLICKHOUSE"/>-->
<!-- <Connection id="CONNECT_03" dbURL="127.0.0.1:3306" database="db1" username="user1" password="******" type="MYSQL"/>-->
<!-- <Connection id="CONNECT_03" database="d:/sqlite_db1.db" batchSize="10000" type="SQLITE"/>-->
<!-- <Connection id="CONNECT_02" dbURL="127.0.0.1:10000" database="db1" username="root" password="b" batchSize="1000" type="HIVE"/>
-->
<!-- <Connection id="CONNECT_02" dbURL="http://127.0.0.1:9200" database="db1" username="elastic" password="******" batchSize="1000" type="ELASTIC"/>
-->
</Graph>任意一个读节点都可以输出到任意一个写节点
输入节点-读数据表
输出节点-写数据表
输入节点-读 excel文件
输出节点-写 excel文件
输入节点-执行数据库脚本
输出节点-垃圾桶,没有任何输出
输入节点-MQ消费者
输出节点-MQ生产者
数据流拷贝节点,位于输入节点和输出节点之间,既是输出又是输入
输入节点-读 redis
输出节点-写 redis
自定义节点,通过嵌入go脚本来实现各种操作
输入节点-执行系统脚本节点
输入节点-读取CSV文件节点
输入节点-读PROMETHEUS节点
输入节点-PROMETHEUS EXPORTER节点
输出节点-写PROMETHEUS节点
输入节点-Http节点
输入节点-读es节点
输出节点-写es节点
输入节点-增量对比节点
输入节点-读hive节点
输入节点-融合查询节点
输入节点-MySQLBinLog节点
输入节点-PG_WAL节点
输入节点-PG_WAL2JSON节点
输入节点-读Hbase节点
输入节点-写Hbase节点
任意一个输入节点都可以连接到任意一个输出节点任意一个输入节点都可以连接到一个拷贝节点一个拷贝节点可以连接到多个输出节点任意一个输入节点都可以连接到一个转换节点拷贝节点不允许连接转换节点
输入节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, DB_INPUT_TABLE |
| script | sqlScript SQL语句 |
| fetchSize | 每次读取记录数 |
| dbConnection | 数据源ID |
| desc | 描述 |
MYSQL、Influxdb 1x、CK、PostgreSQL、Oracle、SQLServer、sqlite
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="1000">
<Script name="sqlScript"><![CDATA[
select * from (select * from t4 limit 100000)
]]></Script>
</Node>输入节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, XLS_READER |
| fileURL | 文件路径+文件名称 |
| startRow | 从第几行开始读取,索引从0开始,0代表第1行(通常是列标题) |
| sheetName | 表名称 |
| maxRow | 最多读几行,*代表全部,10代表读取10行 |
| fieldMap | 字段映射关系,格式:field1=A;field2=B;field3=C 字段名称=第几列 多个字段之间用分号分隔 |
<Node id="XLS_READER_01" type="XLS_READER" desc="输入节点1" fileURL="d:/demo/test1.xlsx" startRow="2" sheetName="人员信息" fieldMap="field1=A;field2=B;field3=C">
</Node>输出节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | 类型, DB_OUTPUT_TABLE | |
| script | insert、delete、update SQL语句 | ck,mysql,sqlite,postgre,oracle,sqlserver |
| batchSize | 每次批提交的记录数 | ck,mysql,sqlite,postgre,oracle 注意influx以输入时的fetchSize为批提交的大小 |
| outputFields | 输入节点读数据时传递过来的字段名称 | influx,ck,mysql,sqlite,postgre,oracle,sqlserver |
| renameOutputFields | 输出节点到目标数据源的字段名称 | influx,ck,mysql,sqlite,postgre,oracle,sqlserver |
| dbConnection | 数据源ID | |
| desc | 描述 | |
| outputTags | 输入节点读数据时传递过来的标签名称 | influx |
| renameOutputTags | 输出节点到目标数据源的标签名称 | influx |
| rp | 保留策略名称 | influx |
| measurement | 表名称 | influx |
| timeOffset | 时间抖动偏移量,用于批量写入时生成不可重复的时间戳 (该功能通过time.Sleep实现,建议通过嵌入脚本增加一个纳秒格式的time列,或调整你的time+tags) |
influx |
MYSQL、Influxdb 1x、CK、PostgreSQL、Oracle、SQLServer、sqlite
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="写influx节点1" dbConnection="CONNECT_02" outputFields="f1;f2;f3;f4" renameOutputFields="c1;c2;c3;c4" outputTags="tag1;tag2;tag3;tag4" renameOutputTags="tag_1;tag_2;tag_3;tag_4" measurement="t5" rp="autogen">
</Node>
<Node id="DB_OUTPUT_02" type="DB_OUTPUT_TABLE" desc="写mysql节点2" dbConnection="CONNECT_03" outputFields="time;f1;f2;f3;f4;tag1;tag2;tag3;tag4" renameOutputFields="time;c1;c2;c3;c4;tag_1;tag_2;tag_3;tag_4" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t1 (time,c1,c2,c3,c4,tag_1,tag_2,tag_3,tag_4) values (?,?,?,?,?,?,?,?,?)
]]></Script>
</Node>输出节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | XLS_WRITER |
| fileURL | 文件路径+文件名称 |
| startRow | 从第几行开始写入 如:数字2代表是第3行(索引从0开始,0代表第1行,1代表第2行) 开始写数据 |
| sheetName | 表名称 |
| outputFields | 输入节点传递过来的字段名称, 格式:field1;field2;field3 |
| renameOutputFields | 字段映射关系,格式:指标=B;年度=C;地区=D 字段名称=第几列 多个字段之间用分号分隔 |
| metadataRow | 输出EXCEL文件中第几行输出字段名称,如:数字1代表是第1行 开始写字段名称 |
| appendRow | true代表追加记录模式,false代表覆盖模式。 |
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="输出节点2" appendRow="true" fileURL="d:/demo/test2.xlsx" startRow="3" metadataRow="2" sheetName="人员信息" outputFields="c1;c3;tag_1" renameOutputFields="指标=B;年度=C;地区=D" >
</Node>输入节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | DB_EXECUTE_TABLE | |
| roolback | 是否回滚 | false不回滚,true回滚 |
| sqlScript | delete、update语句,多条语句之间用分号分隔 | mysql,sqlserver,sqlite,postgre,oracle,ck(不支持delete,update) |
| fileURL | 外部文件 | fileURL优先级别高于sqlScript,两个只能用一个 |
<Node id="DB_EXECUTE_01" dbConnection="CONNECT_01" type="DB_EXECUTE_TABLE" desc="节点1" rollback="false" >
<Script name="sqlScript"><![CDATA[
insert into t_1 (uuid,name) values (13,'aaa');
insert into t_1 (uuid,name) values (14,'bbb');
insert into t_1 (uuid,name) values (15,'ccc');
insert into t_1 (uuid,name) values (1,'aaa')
]]></Script>输出节点
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="节点2" >
</Node>输入节点,阻塞模式
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | MQ_CONSUMER | |
| flag | 默认值:ROCKETMQ | 支持rocketmq |
| nameServer | mq服务器地址,格式:127.0.0.1:8080 | |
| group | mq组名称 | |
| topic | 订阅主题名称 | |
| tag | 标签名称,格式:*代表消费全部标签, tag_1代表只消费tag_1标签 |
<Node id="MQ_CONSUMER_02" type="MQ_CONSUMER" flag="ROCKETMQ" nameServer="127.0.0.1:8080" group="group_1" topic="out_event_user_info" tag="*"></Node>| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | MQ_CONSUMER | |
| flag | 默认值:KAFKA | 支持kafka |
| nameServer | mq服务器地址,格式:127.0.0.1:8080 | |
| group | mq组名称 | |
| topic | 订阅主题名称 | |
| listenerFlag | 1是按分区进行监听 ; 2是按单通道进行监听,topic可以是多个 | |
| allPartition | 是否消费所有分区,true是消费所有分区 | |
| partition | 当allPartition为false时,partition代表消费的分区数字,可按指定分区数字进行消费,适合分流场景 | |
| saslUserName | 用于SASL认证 | |
| saslPassword | 用于SASL认证 |
<Node id="MQ_CONSUMER_03" type="MQ_CONSUMER" flag="KAFKA" nameServer="127.0.0.1:18081" group="group_10" topic="out_event_user_info" listenerFlag="2"></Node>
输出节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | MQ_PRODUCER | |
| flag | 默认值:ROCKETMQ | 支持rocketmq |
| nameServer | mq服务器地址,格式:127.0.0.1:8080 | |
| group | mq组名称 | |
| topic | 订阅主题名称 | |
| tag | 标签名称,格式:tag_1 | |
| sendFlag | 发送模式,1是同步;2是异步;3是单向 | |
| outputFields | 输入节点传递过来的字段名称, 格式:field1;field2;field3 多个字段之间用分号分隔 |
|
| renameOutputFields | 字段映射关系,格式:field1;field2;field3 多个字段之间用分号分隔 |
<Node id="MQ_PRODUCER_01" type="MQ_PRODUCER" flag="ROCKETMQ" nameServer="127.0.0.1:8080" group="group_11" topic="out_event_system_user" tag="tag_1"
sendFlag="3" outputFields="time;tag_1;c2" renameOutputFields="时间;设备;指标" >
</Node>| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | MQ_PRODUCER | |
| flag | 默认值:KAFKA | 支持kafka |
| nameServer | mq服务器地址,格式:127.0.0.1:8080 | |
| topic | 订阅主题名称 | |
| isPartition | true代表指定分区发消息;false代表随机分区发消息 | |
| sendFlag | 发送模式,1是同步;2是异步 | |
| outputFields | 输入节点传递过来的字段名称, 格式:field1;field2;field3 多个字段之间用分号分隔 |
|
| renameOutputFields | 字段映射关系,格式:field1;field2;field3 多个字段之间用分号分隔 |
<Node id="MQ_PRODUCER_02" type="MQ_PRODUCER" flag="KAFKA" nameServer="127.0.0.1:18081" topic="out_event_system_user"
sendFlag="1" outputFields="Offset;Partition;Topic;Value" renameOutputFields="Offset;Partition;Topic;Value" >
</Node>将一个输入节点的数据流输出到多个分支输出节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | COPY_STREAM |
<Node id="COPY_STREAM_01" type="COPY_STREAM" desc="数据流拷贝节点" ></Node>
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="COPY_STREAM_01" order="1" metadata="METADATA_01" ></Line>
<Line id="LINE_02" type="COPY" from="COPY_STREAM_01:0" to="DB_OUTPUT_01" order="2" metadata="METADATA_01"></Line>
<Line id="LINE_03" type="COPY" from="COPY_STREAM_01:1" to="DB_OUTPUT_02" order="2" metadata="METADATA_02"></Line>输入节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | REDIS_READER | |
| nameServer | 127.0.0.1:6379 | |
| password | ****** | |
| db | 0 | 数据库ID |
| isGetTTL | true或false 是否读取ttl信息 | |
| keys | 读取的KEY,多个KEY之间用分号分隔 | 目前只支持读取string,int,float类型内容 |
| patternMatchKey | 默认是false,当设置为true时,证明keys中的内容是进行模式匹配的字符串,如keys=HW_*代表以HW_为前缀的所有key | 设置为true时,默认生成key;value;key_ttl三个固定键,用于后续读取 |
<Node id="REDIS_READER_01" type="REDIS_READER" desc="输入节点1"
nameServer="127.0.0.1:6379" password="******" db="0" isGetTTL="true" keys="a1;a_1" ></Node> <Node id="REDIS_READER_01" type="REDIS_READER" desc="输入节点1" nameServer="127.0.0.1:6379" password="******" db="0"
isGetTTL="true" patternMatchKey="true" keys="HW_*"></Node>输出节点,通过配置patternMatchKey可实现将记录集中的某两个字段写入redis
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | REDIS_WRITER | |
| nameServer | 127.0.0.1:6379 | |
| password | ****** | |
| db | 0 | 数据库ID |
| isGetTTL | true或false 是否写入ttl信息 | |
| patternMatchKey | 默认是false,当设置为true时,证明key是从renameOutputFields中指定的key中取键,从renameOutputFields中指定的value中取值 | 适合将记录集中的某两个字段写入redis |
| outputFields | 目前只支持写string,int,float类型内容 | |
| renameOutputFields | 目前只支持写string,int,float类型内容 |
<Node id="REDIS_WRITER_01" type="REDIS_WRITER" desc="输出节点1" nameServer="127.0.0.1:6379" password="******" db="1"
isGetTTL="true" outputFields="a1;a_1" renameOutputFields="f1;f2" ></Node> <Node id="REDIS_WRITER_01" type="REDIS_WRITER" desc="输出节点1" nameServer="127.0.0.1:6379" password="******" db="1"
isGetTTL="true" patternMatchKey="true" outputFields="key;value;key_ttl" renameOutputFields="key;value;key_ttl" ></Node>自定义节点,可以通过嵌入GO脚本实现各种操作
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | CUSTOM_READER_WRITER |
输入节点-执行系统脚本节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | EXECUTE_SHELL | |
| fileURL | 外部脚本文件位置 | fileURL与Script两者只能出现一个,同时出现时fileURL优先于Script |
| Script | 脚本内容 | |
| outLogFileURL | 控制台输出内容到指定的日志文件 |
<Node id="EXECUTE_SHELL_01" type="EXECUTE_SHELL" desc="节点1" _fileURL="d:/test1.bat" outLogFileURL="d:/test1_log.txt">
<Script><![CDATA[
c:
dir/w
]]></Script>
</Node>输入节点-读取CSV文件节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | CSV_READER | |
| fileURL | CSV文件位置 | |
| fetchSize | 每次读取到内存中的批量数 | 如:可配合influxdb中每次批量提交的记录数,曾测试1W多条数据123个字段,配置100,入库时间为15秒 |
| startRow | 从第几行开始读数据,默认0代表第1行 | 一般0是第一行列名称 |
| fields | 定义输出的字段名称,多个字段间用分号分隔 | field1;field2;field3 |
| fieldsIndex | 定义输出的列,默认0代表第1列,多个字段间用分号分隔;配置成-1代表按顺序读取所有字段 | "2;3;4" |
<Node id="CSV_READER_01" type="CSV_READER" desc="输入节点1" fetchSize="5" fileURL="d:/demo2.csv" startRow="1" fields="field1;field2;field3" fieldsIndex="0;3;4">
</Node>
输入节点-读PROMETHEUS节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | PROMETHEUS_API_READER | |
| url | prometheus服务器地址 | 如:http://127.0.0.1:9090 |
| Script | 查询API内容,只支持/api/v1/query 和 /api/v1/query_range |
如:/api/v1/query?query=my_device_info{deviceCode="设备编码000"}[1d] |
注意:查询返回的结果集中,__name__是度量名称;__TIME__是prometheus入库时的时间戳;__VALUE__是prometheus的value
<Node id="PROMETHEUS_API_READER_1" type="PROMETHEUS_API_READER" url="http://127.0.0.1:9090" >
<Script name="sqlScript">
<![CDATA[
/api/v1/query?query=my_device_info{deviceCode="设备编码000"}[1d]
]]>
</Script>
</Node>
<Node id="DB_OUTPUT_TABLE_1" type="DB_OUTPUT_TABLE" batchSize="10" dbConnection="CONNECT_1" desc="" outputFields="__name__;address;deviceCode;__TIME__;__VALUE__" renameOutputFields="f1;f2;f3;f4;f5" >
<Script name="sqlScript">
<![CDATA[insert into
t_prome_info_bk
(f1,f2,f3,f4,f5)
values (?,?,?,?,?)]]>
</Script>输入节点-PROMETHEUS EXPORTER节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | PROMETHEUS_EXPORTER | |
| exporterAddr | exporter地址, IP:PORT | 如: :10000 |
| exporterMetricsPath | exporter路径, | 如:/EtlEngineExport |
| metricName | 度量名称 | 如:Etl_Engine_Exporter |
| metricHelp | 度量描述 | 如:样本 |
| labels | 标签名称 | 如:deviceCode;address;desc |
<Node id="PROMETHEUS_EXPORTER_1" type="PROMETHEUS_EXPORTER"
exporterAddr=":10000" exporterMetricsPath="/EtlEngineExport"
metricName="Etl_Engine_Exporter" metricHelp="Etl_Engine_Exporter样本"
labels="deviceCode;address;desc">
</Node>prometheus配置文件增加如下内容:
- job_name: "etlengine_exporter"
metrics_path: "/EtlEngineExport"
static_configs:
- targets: ["127.0.0.1:10000"]同时会暴露一个服务地址/pushDataService用于生成数据,postman调试细节如下:
POST 方式
URL http://127.0.0.1:10000/pushDataService ,
Body x-www-form-urlencoded
参数:
"jsondata":{
"labels":{"deviceCode":"设备编码001","address":"南关区","desc":"最大值"},
"value":100
}输出的数据流中会自动添加两个字段,__name__是度量名称,__VALUE__是prometheus的value,
输出节点-写PROMETHEUS节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | PROMETHEUS_API_WRITER | |
| url | prometheus服务器地址 | 如:http://127.0.0.1:9090 |
| metric | 度量名称 | |
| outputFields | 输入节点传递过来的字段名称 | |
| renameOutputFields | prometheus入库时对应的标签名称,数据项与outputFields各项对应 | |
| valueField | prometheus入库时对应的value,数据项与输入节点中已存在的字段名称对应 |
<Node id="DB_INPUT_TABLE_1" type="DB_INPUT_TABLE" fetchSize="1000" dbConnection="CONNECT_1" >
<Script name="sqlScript">
<![CDATA[select f2,f3,f4 from t_prome_info ]]>
</Script>
</Node>
<Node id="PROMETHEUS_API_WRITER_1" type="PROMETHEUS_API_WRITER" url="http://127.0.0.1:9090" metric="my_device_info" outputFields="f2;f3" renameOutputFields="deviceCode;address" valueField="f4" >
</Node>输入节点-Http节点,阻塞模式
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | HTTP_INPUT_SERVICE | |
| serviceIp | 绑定HTTP/HTTPS服务的IP | |
| servicePort | 绑定HTTP/HTTPS服务的端口 | |
| serviceName | 对外暴露的服务名称 | 默认:etlEngineService |
| serviceCertFile | HTTPS服务证书文件位置 | |
| serviceKeyFile | HTTPS服务秘钥文件位置 |
<Node id=""
type="HTTP_INPUT_SERVICE"
serviceIp=""
servicePort="8081"
serviceName="etlEngineService"
serviceCertFile=""
serviceKeyFile="" >
</Node>
postman调试:
http://127.0.0.1:8081/etlEngineService
POST 方式,URL: /etlEngineService , Body:x-www-form-urlencoded
参数:
"jsondata":{
"rows":[
{"deviceCode":"设备编码001","address":"朝阳区","desc":"最大值","value":20},
{"deviceCode":"设备编码002","address":"朝阳区","desc":"最大值","value":18}
]
}
注意:必须传递KEY为rows的数组结构输入节点-读es节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | ELASTIC_READER | |
| index | 索引名称 | |
| sourceFields | 结果集中输出的字段名称 | |
| fetchSize | 每次读取记录数 | |
| Script标签 | DSL查询语法 |
<Node id="ELASTIC_READER_01" dbConnection="CONNECT_02"
type="ELASTIC_READER" desc="节点2" sourceFields="custom_type;username;desc;address" fetchSize="2" >
<Script name="sqlScript"><![CDATA[
{
"query" : {
"bool":{
"must":[
//{
// "term": { "username.keyword": "王先生" }
// "match": { "username": "" }
// },
{
"term": { "custom_type":"t_user_info" }
}
]
}
}
}
]]></Script>
</Node>
<Connection id="CONNECT_02" type="ELASTIC" dbURL="http://127.0.0.1:9200" database="es_db3" username="elastic" password="******" />
输出节点-写es节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | ELASTIC_WRITER | |
| index | 索引名称 | |
| idType | 主键输出方式: 1 代表不指定id,由es系统自己生成20位GUID; 2 代表由idExpress中指定输出的字段名称,从上一个节点的renameOutputFields中进行匹配相同的字段名称的值; 3 代表由idExpress中指定表达式配置,_HW_UUID32 表达式 代表按32位UUID自动生成主键 |
|
| idExpress | 如:idType配置3;该参数配置 _HW_UUID32 | |
| outputFields | 输入节点读数据时传递过来的字段名称 | 按顺序输出字段内容,不按字段名称 |
| renameOutputFields | 输出节点到目标数据源的字段名称 | 按顺序输出字段内容,不按字段名称 |
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="2">
<Script name="sqlScript"><![CDATA[
SELECT "t_user_info" AS custom_type,uname, udesc,uaddress,uid FROM t_u_info
]]></Script>
</Node>
<Node id="ELASTIC_WRITER_01" dbConnection="CONNECT_02" type="ELASTIC_WRITER" desc="节点2"
outputFields="custom_type;uname;udesc;uaddress;uid"
renameOutputFields="custom_type;username;desc;address;uid"
idType="3"
idExpress="_HW_UUID32">
</Node>
<Line id="LINE_01" type="STANDARD" from="DB_INPUT_01" to="ELASTIC_WRITER_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="custom_type" type="string" default="-1" nullable="false"/>
<Field name="username" type="string" default="-1" nullable="false"/>
<Field name="desc" type="string" default="-1" nullable="false"/>
<Field name="address" type="string" default="-1" nullable="false"/>
<Field name="uid" type="string" default="-1" nullable="false"/>
</Metadata>
<Connection id="CONNECT_02" type="ELASTIC" dbURL="http://127.0.0.1:9200" database="es_db3" username="elastic" password="******" />
输入节点-读hive节点
hive.server2.authentication = NONE
hive.server2.authentication = KERBEROS
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, HIVE_READER |
| script | sqlScript SQL语句 |
| fetchSize | 每次读取记录数 |
| dbConnection | 数据源ID |
| authFlag | 认证类型:NONE 或 KERBEROS ,默认是NONE |
| krb5Principal | kerberos用户名称,如:hive.server2.authentication.kerberos.principal = hive/[email protected] 中的hive |
| desc | 描述 |
<Node id="HIVE_READER_01" dbConnection="CONNECT_01"
type="HIVE_READER" desc="节点1" fetchSize="100" >
<Script name="sqlScript"><![CDATA[
select * from db1.t_u_info
]]></Script>
</Node>
<Connection id="CONNECT_01"
dbURL="127.0.0.1:10000" database="db1"
username="root" password="******"
batchSize="1000" type="HIVE"/>
输入节点-增量对比节点
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | INCREMENT | |
| inputSourceConnection | 增量对比源表数据连接ID | |
| inputTargetConnection | 增量对比目标表数据连接ID | |
| inputSourceSQL | 增量对比源表查询语句 | |
| inputTargetSQL | 增量对比目标表查询语句 | |
| inputSourceFetchSize | 增量对比源表每次读取记录数大小,-1为一次性全部读取完毕,注意内存是否够用。 | |
| inputSourcePrimaryKey | 增量对比源表主键字段(参与对比),多字段用分号分隔 | |
| inputSourceCompareKey | 增量对比源表其它字段(参与对比),多字段用分号分隔 | |
| inputSourceMappingKey | 增量对比源表其它字段(不参与对比),多字段用分号分隔 | |
| inputTargetPrimaryKey | 增量对比目标表主键字段(参与对比),多字段用分号分隔 | |
| inputTargetCompareKey | 增量对比目标表其它字段(参与对比),多字段用分号分隔 | |
| inputTargetMappingKey | 增量对比目标表其它字段(不参与对比),多字段用分号分隔 | |
| outputInsertConnection | 增量对比输出新增数据目标表数据连接ID | |
| outputUpdateConnection | 增量对比输出更新数据目标表数据连接ID | |
| outputDeleteConnection | 增量对比输出删除数据目标表数据连接ID | |
| outputInsertMetadata | 增量对比输出新增数据目标表元数据ID | |
| outputUpdateMetadata | 增量对比输出更新数据目标表元数据ID | |
| outputDeleteMetadata | 增量对比输出删除数据目标表元数据ID | |
| outputInsertSQL | 增量对比输出新增数据insert语句 | |
| outputUpdateSQL | 增量对比输出更新数据update语句 | |
| outputDeleteSQL | 增量对比输出删除数据delete语句 | |
| outputInsertFields | 增量对比输出新增数据字段名称,注意顺序要和insert语句中的字段点位符顺序保持一致,多字段用分号分隔 | |
| outputUpdateFields | 增量对比输出更新数据字段名称,注意顺序要和update语句中的字段点位符顺序保持一致,多字段用分号分隔 | |
| outputDeleteFields | 增量对比输出删除数据字段名称,注意顺序要和delete语句中的字段点位符顺序保持一致,多字段用分号分隔 | |
| outputToCopyStream | 默认为false,为false,则增量变化数据在当前节点直接入库(以OUTPUT_TRASH节点结束), 为true,则增量变化数据不在当前节点入库,数据流向后续节点(只能流向 COPY_STREAM ), 由下面的节点来操作数据走向。 |
|
| mustConvertMetadata | 默认为true代表必须按Metadata配置进行格式转换,写效率低但数据质量高, 为false是不按Metadata配置进行格式转换(前提是数据质量比较高),写效率高但数据质量低(有可能在入库过程中因有脏数据导致报错失败) |
<?xml version="1.0" encoding="UTF-8"?>
<Graph>
<Node id="INCREMENT_01" type="INCREMENT"
inputSourceConnection="CONNECT_1"
inputTargetConnection="CONNECT_1"
inputSourceSQL="select * from t_s order by f1 asc"
inputTargetSQL="select * from t_t order by c1 asc"
outputInsertConnection="CONNECT_1"
outputUpdateConnection="CONNECT_1"
outputDeleteConnection="CONNECT_1"
outputInsertSQL="insert into t_t (c1,c2,c3,c4) values (?,?,?,?)"
outputUpdateSQL="update t_t set c3=? ,c4=?,c2=? where c1=?"
outputDeleteSQL="delete from t_t where c1=?"
outputInsertFields="c1;c2;c3;c4"
outputUpdateFields="c3;c4;c2;c1"
outputDeleteFields="c1"
outputInsertMetadata="METADATA_2"
outputUpdateMetadata="METADATA_2"
outputDeleteMetadata="METADATA_2"
inputSourcePrimaryKey="f1"
inputSourceCompareKey="f2;f3"
inputSourceMappingKey="f4"
inputSourceFetchSize="1000"
inputTargetPrimaryKey="c1"
inputTargetCompareKey="c2;c3"
inputTargetMappingKey="c4"
></Node>
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="垃圾桶节点1" > </Node>
<Line id="LINE_01" type="STANDARD" from="INCREMENT_01" to="OUTPUT_TRASH_01" order="1" metadata="METADATA_2"></Line>
<Metadata id="METADATA_1" sortId="1">
<Field name="f1" type="int" default="" nullable="true"/>
<Field name="f2" type="string" default="" nullable="true"/>
<Field name="f3" type="float" default="" nullable="true"/>
<Field name="f4" type="string" default="" nullable="true"/>
</Metadata>
<Metadata id="METADATA_2" sortId="1">
<Field name="c1" type="string" default="" nullable="true"/>
<Field name="c2" type="string" default="" nullable="true"/>
<Field name="c3" type="float" default="" nullable="true"/>
<Field name="c4" type="string" default="" nullable="true"/>
</Metadata>
<Connection sortId="1" id="CONNECT_1" type="MYSQL" dbURL="127.0.0.1:3306" database="db1" username="root" password="******" token="" org=""/>
</Graph>
输入节点-融合查询节点
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, FEDERATION_READER |
| factTableConnectionId | 读取事实表数据源连接ID,只能指定读取一个数据源, factTableConnectionId和dimensionTableConnectionIds可同时设置也可单独设置 |
| factTableQueryFetchSize | 每次读取事实表记录数 ,-1代表一次性全部读取完毕 |
| factTableQuery | 读取事实表sql语句,对应 factTableConnectionId |
| dimensionTableConnectionIds | 读取维表数据源连接ID,多个数据源用分号分隔, factTableConnectionId和dimensionTableConnectionIds可同时设置也可单独设置 |
| dimensionTableQuery | 读取维表对应的sql语句, 多条语句用分号分隔,即对应dimensionTableConnectionIds中所指定的多个数据源连接ID所使用的SQL |
| federationTableAliasName | 融合查询中的表别名,多表之间用分号分隔,注意第一个元素是指定事实表别名,第二个元素及之后是指定维表别名,顺序及数组总数是 factTableConnectionId + dimensionTableConnectionIds 或factTableConnectionId或dimensionTableConnectionIds |
| federationQuery | 融合计算查询语句,支持ANSI SQL标准 |
| desc | 描述 |
读多种类型数据库表(维表和事实表),根据各业务表id进行关联查询,最终将关联结果写入目标表(或文件)
从不同数据源读取用户表t_user_info、 产品表t_product_info 、订单表t_order_info,并在内存中融合计算查询出所有用户的订单信息
<?xml version="1.0" encoding="UTF-8"?>
<Graph desc="融合查询1">
<Node id="FEDERATION_READER_01" type="FEDERATION_READER"
factTableConnectionId="CONNECT_01"
factTableQueryFetchSize="100"
factTableQuery="select o_id,u_id,p_id,o_price,o_number,o_money,o_writetime from t_order_info ORDER BY CAST(SUBSTRING(o_id,3) AS UNSIGNED) ASC"
dimensionTableConnectionIds="CONNECT_02;CONNECT_03"
dimensionTableQuery="select u_id,u_name,u_phone from t_user_info ORDER BY CAST(SUBSTRING(u_id,3) AS UNSIGNED) ASC ;select p_id,p_name,p_contacts,p_desc from t_product_info ORDER BY CAST(SUBSTRING(p_id,3) AS UNSIGNED) ASC "
federationTableAliasName="t_o;t_u;t_p"
federationQuery="SELECT t_u.u_id,t_u.u_name,t_u.u_phone,t_o.o_id,t_o.o_price,t_o.o_number,t_o.o_money,t_o.o_writetime,t_p.p_id,t_p.p_name,t_p.p_contacts,t_p.p_desc FROM t_u inner JOIN t_o ON t_o.u_id=t_u.u_id inner JOIN t_p ON t_o.p_id=t_p.p_id ORDER BY INTEGER(SUBSTRING(t_u.u_id,3)) ASC "
></Node>
<Node id="DB_OUTPUT_01" type="DB_OUTPUT_TABLE" desc="写节点1" dbConnection="CONNECT_04" outputFields="u_id;u_name;u_phone;o_id;o_price;o_number;o_money;o_writetime;p_id;p_name;p_contacts;p_desc" renameOutputFields="u_id;u_name;u_phone;o_id;o_price;o_number;o_money;o_writetime;p_id;p_name;p_contacts;p_desc" batchSize="1000" >
<Script name="sqlScript"><![CDATA[
insert into db1.t_u_o_p_info (u_id,u_name,u_phone,o_id,o_price,o_number,o_money,o_writetime,p_id,p_name,p_contacts,p_desc) values (?,?,?,?,?,?,?,?,?,?,?,?)
]]></Script>
</Node>
<Line id="LINE_01" type="STANDARD" from="FEDERATION_READER_01" to="DB_OUTPUT_01" order="1" metadata="METADATA_1"></Line>
<Metadata id="METADATA_1" sortId="1">
<Field name="u_id" type="string" default="" nullable="true"/>
<Field name="u_name" type="string" default="" nullable="true"/>
<Field name="u_phone" type="string" default="" nullable="true"/>
<Field name="o_id" type="string" default="" nullable="true"/>
<Field name="o_price" type="float" default="0" nullable="false"/>
<Field name="o_number" type="int" default="0" nullable="false"/>
<Field name="o_money" type="float" default="0" nullable="false"/>
<Field name="o_writetime" type="string" default="" nullable="true"/>
<Field name="p_id" type="string" default="" nullable="true"/>
<Field name="p_name" type="string" default="" nullable="true"/>
<Field name="p_contacts" type="string" default="" nullable="true"/>
<Field name="p_desc" type="string" default="" nullable="true"/>
</Metadata>
<Connection id="CONNECT_01" type="MYSQL" dbURL="127.0.0.1:3306" database="db1" username="root" password="******" token="" org=""/>
<Connection id="CONNECT_02" type="MYSQL" dbURL="127.0.0.1:3307" database="db1" username="root" password="******" token="" org=""/>
<Connection id="CONNECT_03" type="MYSQL" dbURL="127.0.0.1:3308" database="db1" username="root" password="******" token="" org=""/>
<Connection id="CONNECT_04" type="MYSQL" dbURL="127.0.0.1:3309" database="db1" username="root" password="******" token="" org=""/>
</Graph>
输入节点-MySQLBinLog节点,阻塞模式
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, MYSQL_BINLOG |
| masterAddress | MySQL数据库地址:127.0.0.1:3306 |
| masterUserName | MySQL数据库登录用户名称 |
| masterPassword | MySQL数据库登录用户密码 |
| masterCanalIncludeTableRegex | 监听的源表名称,可写正式表达式,多个表可用;分隔,格式:db1.t_1 |
| masterCanalExcludeTableRegex | 排除监听的源表名称,与masterCanalIncludeTableRegex是互斥关系 |
| slaveOutputConnectionId | 监听到数据变化后,输出的目标数据源ID |
| slaveOutputMetaDataId | 监听到数据变化后,输出的目标元数据ID,可设置输出数据的格式 |
| outputToCopyStream | false时代表在本节点直接将源表变化的数据入库到目标表 |
| masterExtInfo | 默认无需配置,用于多实例观测服务心跳使用 |
将MySQL数据库中的数据变化输出到其它MySQL、Oracel、PostgreSQL、Elastic等目标数据库中
- MySQL配置文件,配置事项
server-id = 123
log-bin = /opt/mysql/data/mysql-bin
binlog_format = ROW
- etl engine任务配置
<?xml version="1.0" encoding="UTF-8"?>
<Graph runMode="2" desc="读mysqlbin写db">
<Node id="MYSQL_BINLOG_01" type="MYSQL_BINLOG" desc="MYSQL_BINLOG输入节点1"
masterAddress="127.0.0.1:3306"
masterUserName="root"
masterPassword="******"
masterCanalIncludeTableRegex="db1.t_order_info"
masterCanalExcludeTableRegex=""
slaveOutputConnectionId="CONNECT_02"
slaveOutputMetaDataId="METADATA_01"
outputToCopyStream="false"
>
</Node>
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="输出1" >
</Node>
<Line id="LINE_01" type="STANDARD" from="MYSQL_BINLOG_01" to="OUTPUT_TRASH_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="hw_u1.t_1.c1" type="int" default="0" nullable="false"/>
<Field name="hw_u1.t_1.c2" type="string" default="" nullable="false"/>
<Field name="hw_u1.t_222.c3" type="decimal" default="0" nullable="false" dataFormat="2" />
<Field name="hw_u1.t_222.writetime" type="datetime" default="" nullable="false" dataFormat="YYYY-MM-DD hh:mm:ss"/>
<Field name="hw_u1.t_order_info.o_writetime" type="datetime" default="" nullable="false" dataFormat="YYYY-MM-DD hh:mm:ss"/>
</Metadata>
<Connection id="CONNECT_01" dbURL="127.0.0.1:3306" database="db2" username="root" password="******" batchSize="10000" type="MYSQL"/>
<Connection id="CONNECT_02" type="ORACLE" dbURL="127.0.0.1:1521" database="orcl" username="hw_u1" password="******" token="" org=""/>
<Connection id="CONNECT_03" dbURL="127.0.0.1:5432" database="postgres" username="hw_u1" password="******" batchSize="1000" type="POSTGRES"/>
</Graph>
输入节点-PG_WAL节点,阻塞模式
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, PG_WAL |
| masterAddress | PostgreSQL数据库地址:127.0.0.1:3306 |
| masterUserName | PostgreSQL数据库登录用户名称 |
| masterPassword | PostgreSQL数据库登录用户密码 |
| masterDataBase | PostgreSQL数据库名称 |
| masterPublicationTables | 监听的源表名称,多个表可用;分隔,格式:hw_u1.t_1;hw_u2.t_2 |
| slaveOutputConnectionId | 监听到数据变化后,输出的目标数据源ID |
| slaveOutputMetaDataId | 监听到数据变化后,输出的目标元数据ID,可设置输出数据的格式 |
| outputToCopyStream | false时代表在本节点直接将源表变化的数据入库到目标表 |
| masterExtInfo | 默认无需配置,用于多实例观测服务心跳使用 |
将PostgreSQL数据库中的数据变化输出到其它MySQL、Oracel、PostgreSQL、Elastic等目标数据库中。
- postgresql.conf配置文件,配置事项
wal_level = logical
max_replication_slots = 20
max_wal_senders = 20
- pg_hba.conf配置文件,配置事项
host all all 0.0.0.0/0 md5
- 监听的数据表均需要执行以下操作,如表hw_u1.t_4
ALTER TABLE hw_u1.t_4 REPLICA IDENTITY FULL ;
- etl engine任务配置
<?xml version="1.0" encoding="UTF-8"?>
<Graph runMode="2" desc="读pgWal写db">
<Node id="PG_WAL_01" type="PG_WAL" desc="PG_WAL输入节点1"
masterAddress="127.0.0.1:5432"
masterDataBase="postgres"
masterUserName="hw_u1"
masterPassword="******"
masterPublicationTables="hw_u1.t_1"
slaveOutputConnectionId="CONNECT_01"
slaveOutputMetaDataId="METADATA_01"
outputToCopyStream="false"
>
</Node>
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="输出1" >
</Node>
<Line id="LINE_01" type="STANDARD" from="PG_WAL_01" to="OUTPUT_TRASH_01" order="0" metadata="METADATA_01"></Line>
<Metadata id="METADATA_01">
<Field name="hw_u1.t_1.c1" type="int" default="0" nullable="false"/>
</Metadata>
<Connection id="CONNECT_01" dbURL="127.0.0.1:3306" database="db1" username="root" password="******" batchSize="10000" type="MYSQL"/>
<Connection id="CONNECT_02" type="ORACLE" dbURL="127.0.0.1:1521" database="orcl" username="hw_u1" password="******" token="" org=""/>
<Connection id="CONNECT_03" dbURL="127.0.0.1:5432" database="postgres" username="hw_u1" password="******" batchSize="1000" type="POSTGRES"/>
输入节点-PG_WAL2JSON节点,阻塞模式
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, PG_WAL |
| masterAddress | PostgreSQL数据库地址:127.0.0.1:3306 |
| masterUserName | PostgreSQL数据库登录用户名称 |
| masterPassword | PostgreSQL数据库登录用户密码 |
| masterDataBase | PostgreSQL数据库名称 |
| masterAddTables | 监听的源表名称,多个表可用;分隔,格式:hw_u1.t_1;hw_u2.t_2 |
| masterFilterTables | 排除监听的源表名称,多个表可用;分隔,格式:hw_u1.t_1;hw_u2.t_2 ,与masterAddTables是互斥关系 |
| slaveOutputConnectionId | 监听到数据变化后,输出的目标数据源ID |
| slaveOutputMetaDataId | 监听到数据变化后,输出的目标元数据ID,可设置输出数据的格式 |
| outputToCopyStream | false时代表在本节点直接将源表变化的数据入库到目标表 |
| masterExtInfo | 默认无需配置,用于多实例观测服务心跳使用 |
将PostgreSQL数据库中的数据变化输出到其它MySQL、Oracel、PostgreSQL、Elastic等目标数据库中。
wal2json解码器,PostgreSQL需要安装wal2json.so插件 ,
配置参考 PG_WAL 节点输入节点-读Hbase节点
通过thrift2服务接口访问,默认会输出每行的 _rk_ 代表行键。
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, HBASE_READER |
| fetchSize | 每次读取记录数,根据服务端配置决定,建议1000 |
| tableName | 表名称,格式遵循 命名空间:表名称 或 表名称 |
| limitRow | 读取结果集最大上限,0为不限制 |
| maxVersions | 读取结果集所属版本号,根据情况配置,建议越大越好 |
| cols | 读取字段名称,格式遵循 列簇:列标示符 或 列簇,多个列之间用分号分隔,如:info:name;info:age;info:height;data |
| Script | filter过滤器表达式,如:SingleColumnValueFilter('info','age',>=,'binary:24') |
<Node id="HBASE_READER_01" dbConnection="CONNECT_01" type="HBASE_READER" desc="读hbase节点1"
fetchSize="1000"
tableName="t_user_info1"
limitRow="0"
maxVersions="100"
cols="info:name;info:age;info:height;data:address" >
<Script name="sqlScript"><![CDATA[
SingleColumnValueFilter('info','age',>=,'binary:24')
]]></Script>
</Node>
<Connection id="CONNECT_01" dbURL="127.0.0.1:9090" database="" username="" password="" batchSize="1000" type="HBASE"/>
输入节点-写Hbase节点
通过thrift2服务接口访问。
| 属性 | 说明 |
|---|---|
| id | 唯一标示 |
| type | 类型, HBASE_WRITER |
| batchSize | 批量提交记录数,根据服务端配置决定,建议1000 |
| tableName | 表名称,格式遵循 命名空间:表名称 或 表名称 |
| outputFields | 输入节点读数据时传递过来的字段名称 |
| renameOutputFields | 输出节点到目标数据源的字段名称,格式遵循 列簇:列标示符 如: _rk_;info:name;info:age;info:height;data |
| rowKey | 代表行键,从 renameOutputFields 中匹配字段名称并获取,如果不填则系统默认生成 rk_uuid 格式 |
<Node id="HBASE_WRITER_01" dbConnection="CONNECT_02" type="HBASE_WRITER" desc="写hbase节点1"
batchSize="1000"
tableName="hw_ns:t_etl_logs"
outputFields="uuid;username;fileurl;taskdesc;writetime"
renameOutputFields="uuid;username;fileurl;taskdesc;writetime"
rowKey="uuid"
>
</Node>
<Connection id="CONNECT_02" dbURL="127.0.0.1:9090" database="" username="" password="" batchSize="" type="HBASE"/>
元数据文件定义目标数据格式(如输出节点中定义的renameOutputFields或renameOutputTags所对应的字段名称及字段类型)
outputFields是输入节点中数据结果集中的字段名称, 将outputFields定义的字段转换成renameOutputFields定义的字段,其renameOutputFields转换格式通过元数据文件来定义。
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| field | ||
| name | 输出数据源的字段名称 | renameOutputFields, renameOutputTags |
| type | 输出数据源的字段类型 | string,int,int32,float, str_timestamp,decimal, datetime,timestamp,blob |
| default | 默认值 | 当nullable为false时,如果输出值为空字符串,则可以通过default来指定输出的默认值 |
| nullable | 是否允许为空 | false不允许为空,必须和default配合使用。true允许为空。 |
| errDefault | 如果输入数据向输出数据类型转换失败时,是否启动默认值 | 如果设置值,则转换出错时也能向下执行,即出错的值使用该默认值, 如果不设置该值,则转换出错时不能向下执行。 |
| dataFormat | 对日期输出格式的配置 | string -> datetime 或 datetime -> string 需要配置日期格式 日期格式配置如: YYYY-MM-DD hh:mm:ss 或YYYY-MM-DD hh:mm:ssZ+8h |
| dataLen | 对小数位格式的配置 | string -> decimal 格式设置输出数字小数点位数,代表保留小数点后几位,或用于日期输出时定义格式长度 |
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| type | 数据源类型 | INFLUXDB_V1、MYSQL(兼容Doirs和OceanBase)、CLICKHOUSE、SQLSERVER、SQLITE、POSTGRES(兼容Greenplum)、ORACLE、ELASTIC、HIVE、HBSE |
| dbURL | 连接地址 | ck,mysql,influx,postgre,oracle,elastic,hive,sqlserver |
| database | 数据库名称 | ck,mysql,influx,sqlite,postgre,oracle,elastic,hive,sqlserver |
| username | 用户名称 | ck,mysql,influx,postgre,oracle,elastic,hive,sqlserver |
| password | 密码 | ck,mysql,influx,postgre,oracle,elastic,hive,sqlserver |
| token | token名称 | influx 2x |
| org | 机构名称 | influx 2x |
| rp | 数据保留策略名称 | influx 1x |
- 常用数据源连接
<Connection id="CONNECT_01" dbURL="http://127.0.0.1:58086" database="db1" username="user1" password="******" token=" " org="hw" type="INFLUXDB_V1"/>
<Connection id="CONNECT_02" dbURL="127.0.0.1:19000" database="db1" username="user1" password="******" batchSize="1000" type="CLICKHOUSE"/>
<Connection id="CONNECT_03" dbURL="127.0.0.1:3306" database="db1" username="user1" password="******" batchSize="1000" type="MYSQL"/>
<Connection id="CONNECT_04" database="d:/sqlite_db1.db" batchSize="10000" type="SQLITE"/>
<Connection id="CONNECT_05" dbURL="127.0.0.1:10000" database="db1" username="root" password="b" batchSize="1000" type="HIVE"/>
<Connection id="CONNECT_06" dbURL="127.0.0.1:5432" database="db_1" username="u1" password="******" batchSize="1000" type="POSTGRES" />
<Connection id="CONNECT_07" dbURL="http://127.0.0.1:9200" database="db1" username="elastic" password="******" batchSize="1000" type="ELASTIC"/>
<Connection id="CONNECT_08" dbURL="127.0.0.1:1521" database="orcl" username="c##u1" password="******" batchSize="1000" type="ORACLE" />
<Connection id="CONNECT_09" dbURL="127.0.0.1:9090" database="" username="" password="" batchSize="1000" type="HBASE"/>
<Connection id="CONNECT_10" dbURL="127.0.0.1:1433" database="master" username="sa" password="******" batchSize="1000" type="SQLSERVER"/>
| 属性 | 说明 | 适合 |
|---|---|---|
| runMode | 1串行模式;2并行模式 | 默认推荐使用并行模式, 如果需要各流程排序执行,可使用串行模式 |
| 属性 | 说明 | 适合 |
|---|---|---|
| id | 唯一标示 | |
| from | 输入节点唯一标示 | |
| to | 输出节点唯一标示 | |
| type | STANDARD 标准,一进一出,COPY 复制数据流,中间环节复制数据 | |
| order | 串行排序号,按正整数升序排列,在graph属性runMode为1时, 通过配置0,1,2这种方式实现串行执行 |
|
| metadata | 目标元数据ID |
etl_engine -fileUrl ./global6.xml -logLevel debug arg1="d:/test3.xlsx" arg2=上海其中 arg1和arg2是从命令行传递进来的全局变量
<Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="500">
<Script name="sqlScript"><![CDATA[
select * from (select * from t5 where tag_1='${arg2}' limit 1000)
]]></Script>
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="输出节点2" appendRow="true" fileURL="${arg1}" startRow="3" metadataRow="2" sheetName="人员信息" outputFields="c1;c3;tag_1" renameOutputFields="指标=B;年度=C;地区=D" >
配置文件中${arg1} 会在服务运行时通过命令行参数arg1的值d:/test3.xlsx被替换掉
配置文件中${arg2} 会在服务运行时通过命令行参数arg2的值 上海 被替换掉
为方便生成固定格式化内容,系统内置了常用变量,方便用于配置全局变量时动态替换变量值。
内置变量前缀 _HW_
- 时间变量
格式:_HW_YYYY-MM-DD hh:mm:ss.SSS
输出当前系统时间,如: 2022-01-02 19:33:06.108
注意空格通过0x32进行转义,因此正确传递方式是_HW_YYYY-MM-DD0x32hh:mm:ss.SSSYYYY 输出四位年 2022 MM 输出两位月 01 DD 输出两位日 02 hh 输出两位小时 19 mm 输出两位分钟 33 ss 输出两位秒 06 .SSS 输出一个前缀.和三位毫秒 .108
以上部分可随意组合,如:_HW_YYYYMM ,输出202201
-
时间位移变量
在原有时间变量基础上,大写Z字符代表对时、分钟、秒的加减位移。
如格式:_HW_YYYY-MM-DD hh:mm:ss.SSSZ2h45m
输出当前时间累加2小时45分钟后的时间。
如格式:_HW_YYYY-MM-DD hh:mm:ssZ-24h10m
大写字符Z后面跟随负数可实现减位移。
输出当前时间减少24小时10分钟后的时间。
支持的时间频率单位如下:
"ns", "us" (or "µs"), "ms", "s", "m", "h"
在原有时间变量基础上,小写z字符代表对年、月、日的加减位移。
如格式:_HW_YYYY-MM-DD hh:mm:ssz1,2,3
输出当前时间累加1年2个月3天
如格式:_HW_YYYY-MM-DD hhz-1,-2,-3
输出当前时间减少1年2个月3天 -
时间戳变量
格式:_HW_timestamp10
输出当前系统10位时间戳,如:1669450716
格式:_HW_timestamp13
输出当前系统13位时间戳,如:1669450716142
格式:_HW_timestamp16
输出当前系统16位时间戳,如:1669450716142516
格式:_HW_timestamp19
输出当前系统19位时间戳,如:1669450716142516700 -
UUID变量
格式:_HW_UUID32
输出32位UUID,如:D54C3C7163844E4DB4F073E8EEC83328
格式:_HW_uuid32
输出32位UUID,如:d54c3c7163844e4dB4f073e8eec83328
etl_engine -fileUrl ./global6.xml -logLevel debug arg1=_HW_YYYY-MM-DD0x32hh:mm:ss.SSS arg2=_HW_YYYY-MM-DD <Node id="DB_INPUT_01" dbConnection="CONNECT_01" type="DB_INPUT_TABLE" desc="节点1" fetchSize="500">
<Script name="sqlScript"><![CDATA[
select * from (select * from t5 where tag_1='${arg1}' limit 1000)
]]></Script>
<Node id="XLS_WRITER_01" type="XLS_WRITER" desc="输出节点2" appendRow="true" fileURL="${arg2}.xlsx" _fileURL="d:/demo/test2.xlsx" startRow="3" metadataRow="2" sheetName="人员信息" outputFields="c1;c3;tag_1" renameOutputFields="指标=B;年度=C;地区=D" >
可以在任意一个输出节点的 <BeforeOut></BeforeOut> 标签内嵌入自己的业务逻辑,更多介绍
可以增加多个字段,并赋予默认值
package ext
import (
"errors"
"fmt"
"strconv"
"github.com/tidwall/gjson"
"github.com/tidwall/sjson"
)
func RunScript(dataValue string) (result string, topErr error) {
newRows := ""
rows := gjson.Get(dataValue, "rows")
for index, row := range rows.Array() {
//tmpStr, _ := sjson.Set(row.String(), "addCol1", time.Now().Format("2006-01-02 15:04:05.000"))
tmpStr, _ := sjson.Set(row.String(), "addCol1", "1")
tmpStr, _ = sjson.Set(tmpStr, "addCol2", "${arg2}")
newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr)
}
return newRows, nil
}
可以将多个字段合并为一个字段
package ext
import (
"errors"
"fmt"
"strconv"
"github.com/tidwall/gjson"
"github.com/tidwall/sjson"
)
func RunScript(dataValue string) (result string, topErr error) {
newRows := ""
rows := gjson.Get(dataValue, "rows")
for index, row := range rows.Array() {
area := gjson.Get(row.String(),"tag_1").String()
year := gjson.Get(row.String(),"c3").String()
tmpStr, _ := sjson.Set(row.String(), "tag_1", area + "_" + year)
newRows, _ = sjson.SetRaw(newRows, "rows.-1", tmpStr)
}
return newRows, nil
}
<?xml version="1.0" encoding="UTF-8"?>
<Graph>
<Node id="CSV_READER_01" type="CSV_READER" desc="输入节点1" fetchSize="500" fileURL="d:/demo.csv" startRow="1" fields="field1;field2;field3;field4" fieldsIndex="0;1;2;3" >
</Node>
<Node id="OUTPUT_TRASH_01" type="OUTPUT_TRASH" desc="节点2" >
<BeforeOut>
<![CDATA[
package ext
import (
"errors"
"fmt"
"strconv"
"strings"
"time"
"github.com/tidwall/gjson"
"github.com/tidwall/sjson"
"etl-engine/etl/tool/extlibs/common"
"io/ioutil"
"os"
)
func RunScript(dataValue string) (result string, topErr error) {
defer func() {
if topLevelErr := recover(); topLevelErr != nil {
topErr = errors.New("RunScript 捕获致命错误" + topLevelErr.(error).Error())
} else {
topErr = nil
}
}()
newRows := ""
GenLine(dataValue,"db1","autogen","t13","field2","field3;field4")
return newRows, nil
}
//接收的是JSON
func GenLine(dataValue string, db string, rp string, measurement string, fields string, tags string) error {
head := "# DML\n# CONTEXT-DATABASE: " + db + "\n# CONTEXT-RETENTION-POLICY: " + rp + "\n\n"
line := ""
fieldLine := ""
tagLine := ""
_t_ := strings.Split(tags, ";")
_f_ := strings.Split(fields, ";")
rows := gjson.Get(dataValue, "rows")
for _, row := range rows.Array() {
fieldLine = ""
tagLine = ""
for i1 := 0; i1 < len(_t_); i1++ {
tagValue := gjson.Get(row.String(), _t_[i1])
tagLine = tagLine + _t_[i1] + "=\"" + tagValue.String() + "\","
}
tagLine = tagLine[0 : len(tagLine)-1]
for i1 := 0; i1 < len(_f_); i1++ {
fieldValue := gjson.Get(row.String(), _f_[i1])
fieldLine = fieldLine + _f_[i1] + "=" + fieldValue.String() + ","
}
fieldLine = fieldLine[0 : len(fieldLine)-1]
if len(tagLine) > 0 && len(fieldLine) > 0 {
line = line + measurement + "," + tagLine + " " + fieldLine + " " + strconv.FormatInt(time.Now().Add(500*time.Millisecond).UnixNano(), 10) + "\n"
} else {
if len(fieldLine) > 0 {
line = line + measurement + "," + fieldLine + " " + strconv.FormatInt(time.Now().Add(500*time.Millisecond).UnixNano(), 10) + "\n"
}
}
}
if len(line) > 0 {
txt := head + line
fileName := "d:/"+strconv.FormatInt(time.Now().UnixNano(), 10)
WriteFileToDB(fileName, txt)
err1 := os.Remove(fileName)
if err1 != nil {
fmt.Println("删除临时文件失败:", fileName)
return err1
}
}
return nil
}
func WriteFileToDB(fileName string, txt string) {
buf := []byte(txt)
err := ioutil.WriteFile(fileName, buf, 0666)
if err != nil {
fmt.Println("写入文件失败:", err)
return
} else {
cmdLine := "D:/software/influxdb-1.8.10-1/influx.exe -import -path=" + fileName + " -host 127.0.0.1 -port 58086 -username u1 -password 123456 -precision=ns"
//fmt.Println("cmdLine:",cmdLine)
common.Command3("GB18030", "cmd", "/c", cmdLine)
}
}
]]>
</BeforeOut>
</Node>
<Line id="LINE_01" type="STANDARD" from="CSV_READER_01" to="OUTPUT_TRASH_01" order="0" metadata="METADATA_03">线标注</Line>
<Metadata id="METADATA_03">
<Field name="field1" type="string" default="-1" nullable="false"/>
<Field name="field2" type="string" default="-1" nullable="false"/>
<Field name="field3" type="string" default="-1" nullable="false"/>
<Field name="field4" type="string" default="-1" nullable="false"/>
</Metadata>
</Graph>
