JuliaCon 2023 workshop | Tue, July 25, 9:00-12:00 ET (15:00-17:00 CEST)
👀 watch the workshop LIVE recording (coming soon)
⚠️ Make sure togit pullthis repo right before starting the workshop in order to ensure you have access to the latest updates
- Getting started
- Brief intro to Julia for HPC 📖
- Performance, CPUs, GPUs, array and kernel programming
- Presentation of the challenge of today 📖
- Optimising injection/extraction from a heterogeneous reservoir
- Hands-on I - solving the forward problem 💻
- Steady-state diffusion problem
- The accelerated pseudo-transient method
- Backend agnostic kernel programming with math-close notation
- Presentation of the optimisation problem 📖
- Tha adjoint method
- Julia and the automatic differentiation (AD) tooling
- Hands-on II - HPC GPU-based inversions 💻
- The adjoint problem using AD
- GPU-based adjoint solver using Enzyme.jl from ParallelStencil.jl
- Gradient-based inversion using Optim.jl
- Wrapping-up
- Demo: Multi-GPU inversion using AD and distributed memory parallelisation with ImplicitGlobalGrid.jl
- What we learned - recap
The goal of today's workshop is to develop a fast iterative GPU-based solver for elliptic equations and use it to:
- Solve a steady state subsurface flow problem (geothermal operations, injection and extraction of fluids)
- Invert for the subsurface permeability having a sparse array of fluid pressure observations
- Verify that the approach works using a distributed memory parallelisation on multiple GPUs
We will not use any "black-box" tooling but rather try to develop concise and performant codes (300 lines of code, max) that execute on multiple GPUs. We will also use automatic differentiation (AD) capabilities and the differentiable Julia stack to automatise the calculation of the adjoint solutions in the gradient-based inversion procedure.
The main Julia packages we will rely on are:
- ParallelStencil.jl for architecture agnostic
- ImplicitGlobalGrid.jl for distributed memory parallelisation
- Enzyme.jl for AD on GPUs
- CairoMakie.jl for visualisation
- Optim.jl to implement an optimised gradient-descent procedure
The workshop promotes "hands-on". Blanked-out scripts for most of the steps are available in the scripts folder. Solutions scripts (following the s_xxx.jl pattern) will are available in the scripts_solutions folder.
🚀 Note that we will not extensively investigate performance during this workshop because of time limitations. However, there will be talk given by Sam Omlin focussing specifically on this topic: Scalable 3-D PDE Solvers Tackling Hardware Limit.
- The Julia language: https://julialang.org
- PDE on GPUs ETH Zurich course: https://pde-on-gpu.vaw.ethz.ch
- SCALES workshop: https://github.com/PTsolvers/Julia-HPC-Scales
Before we start, let's make sure that everyone can run the presented codes on either their local or remote CPU, ideally GPU machine.
⚠️ We are using some exciting latest features from the Julia GPU and AD stack which requires to run on Julia 1.9.2, using:
Enzyme v0.11.6
ImplicitGlobalGrid v0.13.0
MPI v0.20.12
ParallelStencil v0.8.1
for a smooth experience.
The fast-track is to clone this repo
git clone https://github.com/PTsolvers/gpu-workshop-JuliaCon23.git
Once done, navigate to the cloned folder, launch Julia (we will demo the workshop using VSCode on a Nvidia A100) and activate the environment by typing
] activate .from within the REPL. Then follow it up with
] instantiateto instantiate the project and its dependencies.
If all went fine, you should be able to execute the following command in your Julia REPL:
julia> include("scripts/visu_2D.jl")which will produce this figure:

The Julia at scale effort:
- Julia is fast as lower level code
- Julia is interactive as higher-level code
Julia is cool 🙂 exactly for that
Today, we will develop code that:
- Runs on multiple graphics cards using the Julia language
- Uses a fully local and iterative approach (scalability)
- Retrieves automatically the vector-Jacobian product (VJP) using automatic differentiation (AD)
- (All scripts feature about 300 lines of code)
Too good to be true? Hold on 🙂 ...
- It's around for more than a decade
- It shows massive performance gain compared to serial CPU computing
- First exascale supercomputer, Frontier, is full of GPUs



Taking a look at a recent GPU and CPU:
- Nvidia Tesla A100 GPU
- AMD EPYC "Rome" 7282 (16 cores) CPU
| Device | TFLOP/s (FP64) | Memory BW TB/s | Imbalance (FP64) |
|---|---|---|---|
| Tesla A100 | 9.7 | 1.55 | 9.7 / 1.55 × 8 = 50 |
| AMD EPYC 7282 | 0.7 | 0.085 | 0.7 / 0.085 × 8 = 66 |
Meaning: we can do about 50 floating point operations per number accessed from main memory. Floating point operations are "for free" when we work in memory-bounded regimes.
Moreover, the cost of evaluating a first derivative
q[ix] = -D * (A[ix+1] - A[ix]) / dxconsists of:
- 1 read (
A) + 1 write (q) =>$2 × 8$ = 16 Bytes transferred - 1 addition + 1 multiplication + 1 division => 3 floating point operations
assuming $D$, $∂x$ are scalars, $q$ and $A$ are arrays of Float64 (read from main memory)
💡 Requires to re-think the numerical implementation and solution strategies
GPUs have a large memory bandwidth, which is crucial since we are memory bounded.
👉 Let's assess how close from memory copy (1355 GB/s) we can get solving a 2D diffusion problem:
on an Nvidia Tesla A100 GPU (using a simple perftest.jl script).
Because it is still challenging:
- Very few codes use it efficiently.
- It requires to rethink the solving strategy as non-local operations will kill the fun.
The goal fo today is to solve a subsurface flow problem related to injection and extraction of fluid in the underground as it could occur in geothermal operations. For this purpose, we will solve an elliptic problem for fluid pressure diffusion, given impermeable boundary conditions (no flux) and two source terms, injection and extraction wells. In addition, we will place a low permeability barrier in-between the wells to simulate a more challenging flow configuration. The model configuration is depicted hereafter:

Despite looking simple, this problem presents several challenges to be solved efficiently. We will need to:
- efficiently solve an elliptic equation for the pressure
- handle source terms
- handle spatially variable material parameters
💡 For practical purposes, we will work in 2D, however everything we will develop today is readily extensible to 3D.
The corresponding system of equation reads:
where
We will use an accelerated iterative solving strategy combined to a finite-difference discretisation on a regular Cartesian staggered grid:

The iterative approach relies in replacing the 0 in the mass balance equation by a pseudo-time derivative
Introducing the residual
We will stop the iterations when the max(abs.(RPf)) < ϵtol.
This rather naive iterative strategy can be accelerated using the accelerated pseudo-transient method (Räss et al., 2022). In a nutshell, pseudo-time derivative can also be added to the fluxes turning the system of equations into a damped wave equation. The resulting augmented system of accelerated equations reads:
Finding the optimal damping parameter entering the definition of
Let's get started. In this first hands-on, we will work towards making an efficient iterative GPU solver for the forward steady state flow problem.
The first script we will look at is geothermal_2D_noacc.jl. This script builds upon the visu_2D.jl scripts and contains the basic ingredients to iteratively solve the elliptic problem for fluid pressure diffusion with spatially variable permeability.
👉 Let's run the geothermal_2D_noacc.jl script and briefly check how the iteration count normalised by nx scales when changing the grid resolution.
As you can see, the overall iteration count is really large and actually scales quadratically with increasing grid resolution.
To address this issue, we can implement the accelerated pseudo-transient method (Räss et al., 2022). Practically, we will define residuals for both x and y fluxes (Rqx, Rqy) and provide an update rule based on some optimal numerical parameters consistent with the derivations in (Räss et al., 2022).
This acceleration implemented in the geothermal_2D.jl script, we now (besides other changes):
- reduced the cfl from
clf = 1 / 4.1tocfl = 1 / 2.1 - changed
dτ = cfl * min(dx, dy)^2tovdτ = cfl * min(dx, dy) - introduced a numerical Reynolds number (
re = 0.8π)
👉 Let's run the geothermal_2D.jl script and check how the iteration count scales as function of grid resolution.
💡 Have a look at SCALES workshop repo if you are interested in working out the intermediate steps.
Now that we have settled the algorithm, we want to implement it in a backend-agnostic fashion in order to overcome the two-language barrier, having a unique script to allow for rapid prototyping and efficient production use. This script should ideally target CPU and various GPU architectures and allow for "math-close" notation of the physics. For this purpose, we will use ParallelStencil.
👉 Let's open the geothermal_2D_ps.jl script and add the missing pieces following the steps.
First, we need to use ParallelStencil and the finite-difference helper module:
using ParallelStencil
using ParallelStencil.FiniteDifferences2DThen, we can initialise ParallelStencil choosing the backend (Threads, CUDA, AMDGPU), the precision (Float32, Float64, or others, complex) and the number of spatial dimensions (1, 2, or 3). For Nvidia GPUs in double precision and 2D it will be
@init_parallel_stencil(CUDA, Float64, 2)Then, we will move the physics computations into functions and split them into 4 functions:
@parallel function residual_fluxes!(Rqx, Rqy, ???)
@inn_x(Rqx) = ???
@inn_y(Rqy) = ???
return
end
@parallel function residual_pressure!(RPf, ???)
@all(RPf) = ???
return
end
@parallel function update_fluxes!(qx, qy, ???)
@inn_x(qx) = ???
@inn_y(qy) = ???
return
end
@parallel function update_pressure!(Pf, ???)
@all(Pf) = ???
return
endUse the helper macros from the ParallelStencil.FiniteDifferences2D module to implement averaging, differentiating and inner point selection. Type:
julia> ?
help?> FiniteDifferences2Dfor more information on the available macros.
Next, we can change the initialisation of arrays from e.g. zeros(Float64, nx, ny) to @zeros(nx, ny). Also, note that to "upload" an array A to the defined backend you can use Data.Array(A) and to "gather" it back as CPU array Array(A).
Then we have to call the compute functions from within the iteration loop using the @parallel keyword:
@parallel residual_fluxes!(Rqx, Rqy, ???)
@parallel update_fluxes!(qx, qy, ???)
@parallel residual_pressure!(RPf, ???)
@parallel update_pressure!(Pf, ???)As last step, we have to make sure to "gather" arrays for visualisation back to CPU arrays using Array().
👉 Run the geothermal_2D_ps.jl script and check execution speed on CPU and GPU (if available). Have a look at the s_geothermal_2D_ps.jl script if you are blocked or need hints.
💡 Have a look at SCALES workshop repo if you are interested in the intermediate steps going from array to kernel programming on both CPU and GPU.
In the first part of this workshop, we have learned how to compute the fluid pressure and fluxes in the computational domain with a given permeability distribution. In many practical applications the properties of the subsurface, such as the permeability, are unknown or poorly constrained, and the direct measurements are very sparse as they would require extracting the rock samples and performing laboratory experiments. In many cases, the outputs of the simulation, i.e. the pressure and the fluxes, can be measured in the field at much higher spatial and temporal resolution. Therefore, it is useful to be able to determine such a distribution of the properties of the subsurface, that the modelled pressures and fluxes match the observations as close as possible. The task of finding this distribution is referred to as the inverse modelling. In this session, we will design and implement the inverse model for determining the permeability field, using the features of Julia, such as GPU programming, automatic differentiation, and numerical optimization packages.
In the following, we will refer to the model that maps the permeability to the pressure and the fluxes as the forward model. Opposed to the forward model, the inputs of the inverse model are the observed values of the pressure and the fluxes, and the outputs are the distributions of the subsurface properties. The results of the inverse modelling can be then used to run a forward model to check if the modelled quantities indeed match the observed ones.
Let's define the results of the forward model as the mapping
The residual of the problem is a vector containing the left-hand side of the system of governing equations, written in a such a form in which the right-hand side is

To quantify the discrepancy between the results of the forward model

where
The goal of the inverse modelling is to find such a distribution of the parameter

Therefore, the inverse modelling is tightly linked to the field of mathematical optimization. Numerous methods of finding the optimal value of
The gradient of the objective function with respect to the permeability
Adjoint state method allows to compute the point-wise gradient of the scalar-valued objective function in an efficient manner by solving the adjoint equation, which is a linear system of equations having the same structure and the forward system.
💡 To save time, we have implemented the adjoint solver for you, but if you're interested in the detailed derivation of the adjoint equations, you can read them below.
Derivation
The objective function
|
(1) |
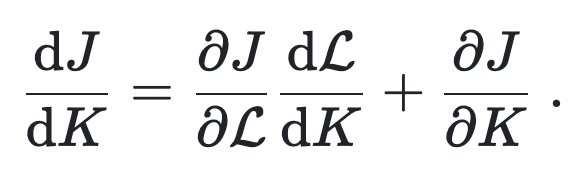
In this expression, some of the terms are easy to compute. If the cost function is defined as a square of the difference between the modelled solution and observed values (see above), then
⚠️ In this section we use the standard notation for partial and total derivatives. This is correct for the finite-dimensional analysis, i.e. for discretised versions of the equations. However, in the continuous case, the derivatives are the functional derivatives, and a more correct term for the objective function would be the "objective functional" since it acts on functions. In the workshop, we'll only work with the discretised form of equations, so we use the familiar notation to keep the explanation simple.
Note that the solution
|
(2) |
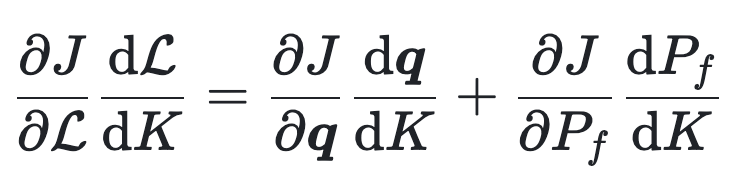
To compute this tricky term, we note that the solution to the forward problem nullifies the residual
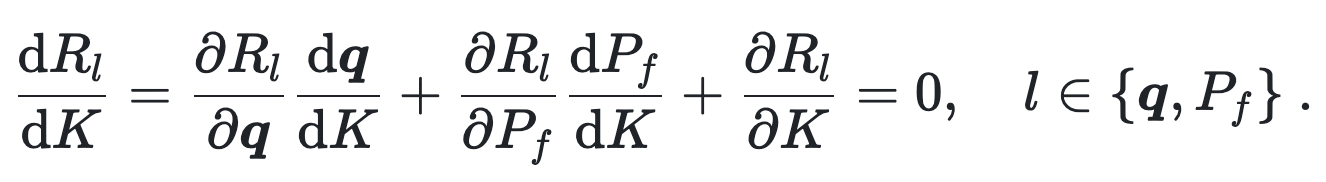
This is the system of equations which could be solved for
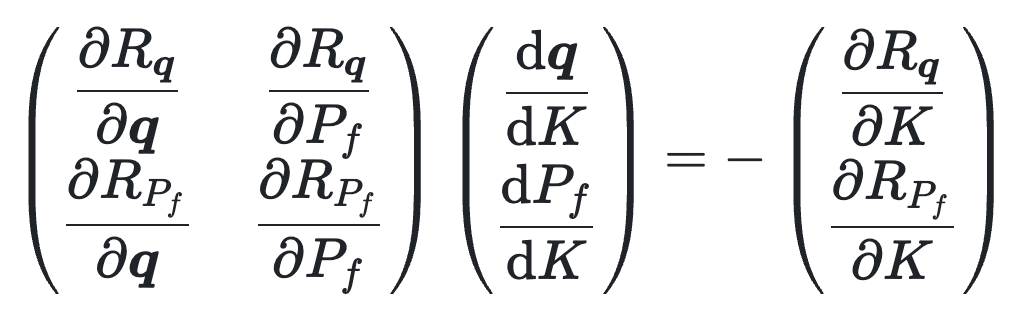
One could solve this system of equations to compute the derivatives. However, the sizes of the unknowns
Luckily, we are only interested in evaluating the objective function gradient (1), which has the size of
|
(3) |
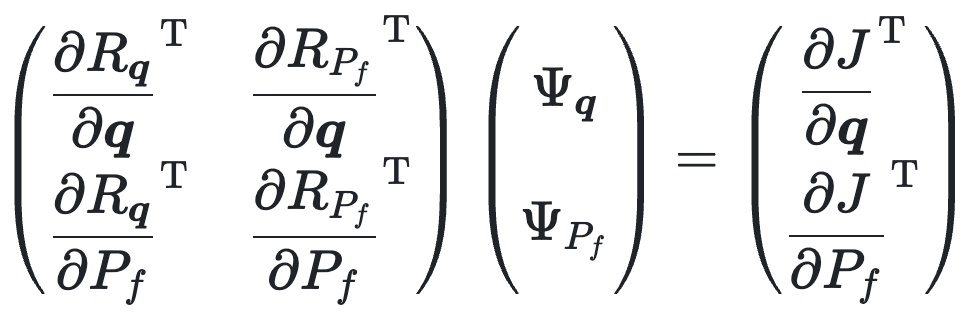
The sizes of the unknowns

Phew, there is a lot to process 😅! We now established a very efficient way of computing point-wise gradients of the objective function. Now, we only need to figure out how to solve the adjoint equation (3).
Pseudo-transient adjoint solver
In the same way that we solve the steady-state forward problem by integrating the equations given by residual
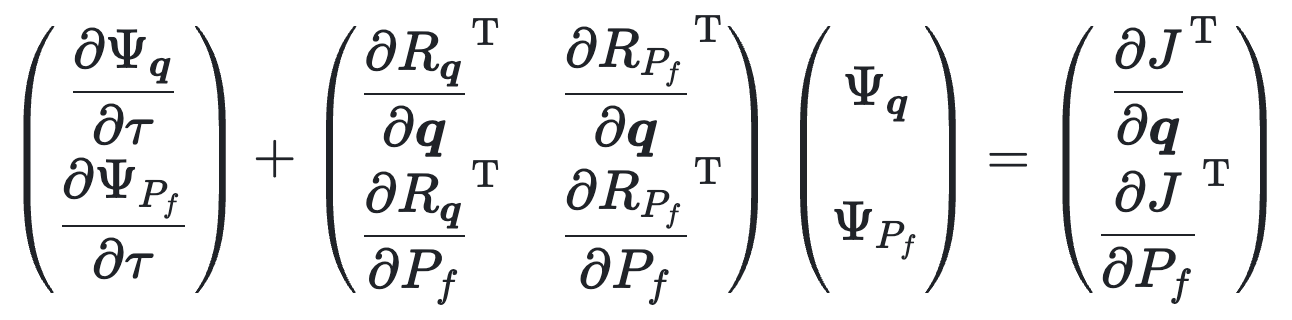
With this approach, we never need to explicitly store the matrix of the adjoint problem. Instead, we only need to evaluate the product of this matrix and the adjoint variables at the current iteration in pseudo-time. It is very similar to just computing the residuals of the current forward solution.
📖 Note that the matrix in the adjoint equation is actually the transposed Jacobian matrix of the forward problem. Evaluating the product of the Jacobian matrix and a vector is a very common operation in computing, and this product is commonly abbreviated as JVP (Jacobian-vector product). Computing the product of the transposed Jacobian matrix and a column vector is equivalent to the product of the row vector and the same Jacobian. Therefore, it is termed VJP (vector-Jacobian product).
To solve the adjoint problem, we need to evaluate the VJPs given the residuals for the forward problem. It is possible to do that either analytically, which involves manual derivation for the transposed Jacobian for every particular system of equations, or numerically in an automated way, using the automatic differentiation.
The output of the adjoint solver is the adjoint pressure
To compute the product of the adjoint solution and the matrix of partial derivatives, we will use automatic differentiation.
Automatic differentiation (AD) allows evaluating the gradients of functions specified by code. Using AD, the partial derivatives are evaluated by repeatedly applying the chain rule of differentiation to the sequence of elementary arithmetic operations constituting a computer program.
💡 Many constructs in computer programs aren't differentiable, for example, I/O calls or system calls. AD tools must handle such cases.
Automatic differentiation is a key ingredient of differentiable programming, a programming paradigm enabling gradient-based optimisation of the parameters of an arbitrary computer program.
Julia has a rich support for differential programming. With the power of tools like Enzyme.jl it is possible to automatically compute the derivatives of arbitrary Julia code, including the code targeting GPUs.
One of the main building blocks in many optimization algorithms involves computing the Jacobian-vector product (VJP). AD tools simplify evaluating VJPs by generating the code automatically given the target function.
Let's familiarise with Enzyme.jl, the Julia package for performing AD.
💡 There are many other Julia packages for performing AD, e.g., Zygote.jl. In this tutorial, we use Enzyme as it supports some features currently missing in other packages, e.g., differentiating mutating functions and GPU kernels.
Let's start with a simple example:
julia> using Enzyme
julia> f(ω,x) = sin(ω*x)
f (generic function with 1 method)
julia> ∇f(ω,x) = Enzyme.autodiff(Reverse,f,Active,Const(ω),Active(x))[1][2]
∇f (generic function with 1 method)
julia> @assert ∇f(π,1.0) ≈ π*cos(π)In this line: ∇f(x) = Enzyme.autodiff(Reverse,f,Active,Active(x))[1][1], we call Enzyme.autodiff function, which computes the partial derivatives. We pass Reverse as a first argument, which means that we use the reverse mode of accumulation (see below). We mark the arguments as either Const or Active to specify which partial derivatives are computed.
It is possible to use Enzyme.jl directly for more complicated tasks, such as computing the partial derivatives of vector-valued functions. But we will use the recently added feature of ParallelStencil, which allows to greatly simplify the gradient computations.
Let's extend the example with sine computation to the mutating vector-valued kernel:
julia> using ParallelStencil, ParallelStencil.FiniteDifferences2D
julia> @init_parallel_stencil(Threads, Float64, 2)
julia> @parallel compute_sin!(r, ω, x) = (@all(r) = sin(ω*@all(x)); nothing)
...
julia> r = zeros(2, 2); r̄ = ones(2, 2)
...
julia> x = rand(2, 2); x̄ = zeros(2, 2)
...
julia> @parallel ∇=(r->r̄, x->x̄) compute_sin!(r, float(π), x)
julia> x̄ ≈ π.*cos.(π.*x)
trueThis syntax allows computing vector-Jacobian products (VJPs):
@parallel ∇=(r->r̄, x->x̄) compute_sin!(r, float(π), x)In this case, r̄ is an input vector, x̄ is a storage for the partial derivative (VJP). We use the convention, according to which the bar above the variable denotes the "adjoint" of that variable.
Now we are familiar with Enzyme.jl and how to use it with ParallelStencil.jl. Let's begin the hands-on activity! 🚀
In this section, we will implement the gradient-based inversion algorithm for the permeability of the subsurface. In the first session we used the model setup involving a permeability barrier in the center of the computational domain. Now, we will try reconstruct this permeability barrier knowing only the "observed" values of the pressure.
💡 We will use the solution to the forward model as a synthetic dataset instead of real observations. We will only only a subset of the pressure field to emulate the sparsity of the datasets in the real world.
In this exercise, we will implement the gradient descent algorithm to progressively update the permeability
We will match only the "observed" pressure field
First, we will refactor the code in such a way that the forward (and adjoint) solution loop is in a separate function.
Start from the file geothermal_2D_ps_inv.jl. Copy the implementations of all the kernels from the previous file with the forward solver.
Note that there is one additional kernel smooth_d! in this file. This kernel smooths the input field using several steps of diffusion. We wil use this kernel to implement the regularization of the inverse problem. In lay terms, we prevent the inverted permeability field from having sharp gradients. The reasons why it is needed and the derivation of the regularization terms are beyond the scope of this workshop.
You can find two new functions, forward_solve! and adjoint_solve!. This functions contain all the functionality required for computing the forward and inverse problem, respectively. Try to fill in the missing arguments into the @parallel kernel invocations. Remember that for each variable the corresponding "adjoint" variable has a bar, e.g., qx->q̄x.
When you're done, call the forward solve in the main function after the line @info "Synthetic solve":
@info "Synthetic solve"
forward_solve!(logK, fwd_params...; visu=fwd_visu)The ... syntax in Julia means that we expand the named tuple into the comma-separated list of function arguments. We also make visualisation optional, to avoid excessive plotting in the inverse solver.
You can temporarily comment the rest of the code and run it to make sure that it works.
💡 Note that we pass the logarithm of permeability
$K$ into both the forward and adjoint solvers. This is necessary since the permeability in the barrier is 6 orders of magnitude lower that that of the surrounding subsurface. This is characteristic for the Earth's crust. Using the logarithm of the permeability as the control variable makes the inversion procedure much more robust, and avoids accidentally making the permeability negative, with would result in instability.
We have two more new functions in the file geothermal_2D_ps_inv.jl, namely loss and ∇loss!. "Loss" is just another name for the objective function (which is also often called the "cost function"). It is obvious that in order to evaluate the loss function, one has to run the forward solver, and to evaluate the gradient, one needs to make the forward solve, followed by adjoint solve, and finally evaluate the gradient. Replace the ??? with corresponding calls to the forward and adjoint solvers, and finally call the gradient of the residual_fluxes! function. Look at the mathematical definition of the gradient R̄qx and R̄qy.
In real world, the observations are sparse. We try to mimic this sparseness by saving only a subset of the synthetic solve results. We introduce the ranges containing the coordinates of observations:
# observations
xobs_rng = LinRange(-lx / 6, lx / 6, 8)
zobs_rng = LinRange(0.25lz, 0.85lz , 8)Then compute the indices of the grid cells corresponding to these locations:
ixobs = floor.(Int, (xobs_rng .- xc[1]) ./ dx) .+ 1
izobs = floor.(Int, (zobs_rng .- zc[1]) ./ dz) .+ 1And finally, store only the pressures at these locations after the synthetic solve:
@info "Synthetic solve"
#= ??? =#
# store true data
Pf_obs = copy(Pf[ixobs, izobs])As we'll see, the quality of inversions is significantly affected by the availability of the data.
Try to execute the functions loss and ∇loss! in the code to make sure your implementation works as expected.
We can use the functions loss and ∇loss! to iteratively update the permeability. We introduce the following shortcuts using the Julia closures syntax:
J(_logK) = loss(_logK, fwd_params, loss_params)
∇J!(_logK̄, _logK) = ∇loss!(_logK̄, _logK, fwd_params, adj_params, loss_params; reg)The functions J and ∇J! now compute the loss function and its gradient in a black-box fashion. That means that we use a robust implementation of a production-level gradient-based optimisation algorithm. Many such algorithms are implemented in the package Optim.jl. Implementations in Optim.jl include automatic search for the step size, and improved search directions for faster convergence then just the direction of the steepest descent.
We need to initialise the permeability field with some value different from the correct answer. Here we just remove the low-permeability barrier:
K .= k0_μ
logK .= log.(K)Then we specify the optimisation parameters for Optim.jl:
opt = Optim.Options(
f_tol = 1e-2,
g_tol = 1e-6,
iterations = 20,
store_trace=true, show_trace=true,
)We pick the tolerance, maximum number of iterations, indicate that we want to save the convergence history (trance) and show the progress.
Use the function optimize from Optim.jl to optimize the objective function J with gradient ∇J!. Refer to the documentation of Optim.jl for the details. Use the LBFGS optimizer and the options stored in the opt variable.
In the visualisation part, we retrieve the convergence history:
errs_evo = Optim.f_trace(result)
errs_evo ./= errs_evo[1]
iters_evo = 1:length(errs_evo)
plt.err[1] = Point2.(iters_evo, errs_evo)Congratulations 🎉, you successfully implemented the full inversion procedure! Despite being very simple and not robust enough, the algorithm reproduces the approximate location and the shape of the low-permeability barrier.
As final step, we can port our inversion workflow to distributed memory parallelisation on. e.g.. multiple GPUs using ImplicitGlobalGrid.jl.
The iterative workflow we introduced is readily extensible to supercomputing workflows, as we can leverage distributed memory parallelisation on CPUs and GPUs. To demonstrate this feature we will port the geothermal_2D_ps_inv.jl script to distributed memory parallelisation on multiple GPUs. The resulting script geothermal_2D_ps_igg_inv.jl implements the minor changes needed to achieve our final goal.
Among the changes, we need now to use new packages:
using ImplicitGlobalGrid
using MPIdefine (costly) global operations:
sum_g(A) = (sum_l = sum(A); MPI.Allreduce(sum_l, MPI.SUM, MPI.COMM_WORLD))
max_g(A) = (max_l = maximum(A); MPI.Allreduce(max_l, MPI.MAX, MPI.COMM_WORLD))and a few other bits, mostly related to handling initial conditions with respect to local to global coordinates. The general approach we follow in here goes back to what is exemplified in more details in this PDE on GPU course.
The really cool thing is that the physics calculations remain unchanged! The only detail there is that we need to add "halo updates" for both the fluxes and adjoint fluxes, as well as for adjoint pressure since we apply boundary conditions on tha field.
In addition, combining ImplicitGlobalGrid.jl to ParallelStencil.jl allows for hiding MPi coomunication behind inner local domain computations via the @hide_communication macro.
The last bit is that we need to replace the Optim.jl LBFGS()-based inversion algorithm by a custom gradient descent in order to avoid any global operations (that would require communication for global reductions):
for igd in 1:ngd
(me==0) && printstyled("> GD iter $igd \n"; bold=true, color=:green)
# evaluate gradient of the cost function
∇J!(dJ_dlogK, logK)
# update logK
γ = Δγ / max_g(abs.(dJ_dlogK))
@. logK -= γ * dJ_dlogK
(me==0) && @printf " min(K) = %1.2e \n" minimum(K)
# loss
push!(cost_evo, J(logK))
(me==0) && @printf " --> Loss J = %1.2e (γ = %1.2e)\n" last(cost_evo)/first(cost_evo) γ
endWith that we can see that we now can run our fully automatised AD-powered adjoint-based inversion on 4 Nvidia A100 GPUs 🚀:

In this workshop, we learned about:
- a simple but efficient way to accelerate iterative solvers using a physics-motivated algorithmic optimisation technique
- a concise and backend-agnostic programming approach in Julia to leverage the computing power of graphic processing units (ParallelStencil.jl)
- an effective inversion approach using the adjoint state method and retrieving the adjoint variables automatically via automatic differentiation tools on GPUs
- a few minor modification steps to execute the inversion script on multiple GPUs allowing for massively parallel large scale inversions on GPU-powered supercomputers
Congrats for making it up to here 💯