黑龙江某医学检验中心的新冠病毒OA系统后端,主要给医学检验中心做核酸、抗体、双联(抗体+核酸)报告的生成与导出。截至到目前(2020年11月3日)已经生成了50多万个核酸、抗体和双联报告,算是鄙人小渣硕为祖国的新冠疫情事业出的一份力。
前端使用的是Vue2.x+Elementui。地址:https://github.com/MaShantao/JzyOA
后端使用SSM进行编码,使用Java Poi做报告的生成,后端解决跨域请求。编译器用的是eclipse,从16年开始就一直用eclipse,一直就延续下来了。项目后端比较简单,就是纯SSM,比较值得一说的是数据库建模工具PowerDesigner、PDF模板生成和前后端的后端处理跨域。
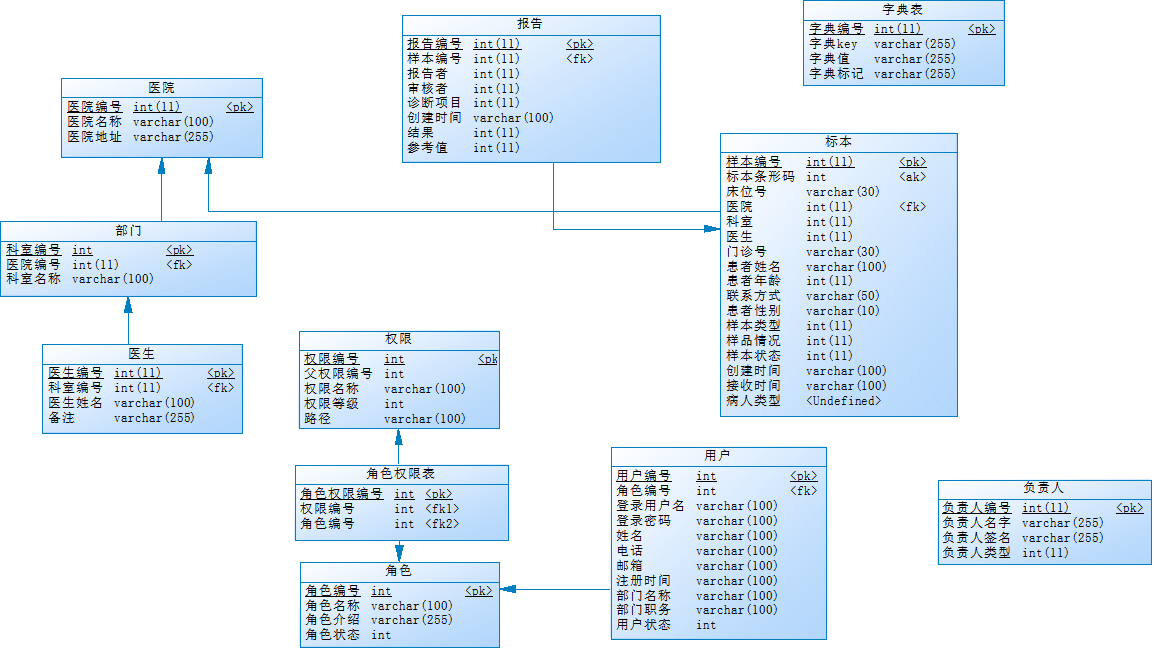
数据库建模使用的是国内比较流行的Powerdesigner。由于项目的数据不是很强关联,所以数据库在设计的时候,有些表之间没有建立关联,这是根据具体业务来做的。
报告的格式是PDF,原先想用word模板生成PDF,但是查了很多资料,发现相应的工具很少,目前比较成熟的工具,比如Spire需要购买版权,否则生成的PDF会在第一页加上人家的广告。所以就选择了根据PDF模板来生成PDF,使用的工具是Java Poi。具体步骤如下。
首先保证得有PDF模板,如果模板是word等其他格式的,可以使用wps导出为PDF。
使用Adobe旗下的Acrobat(一款专门用来编辑PDF的软件)。
原始的PDF模板如下:

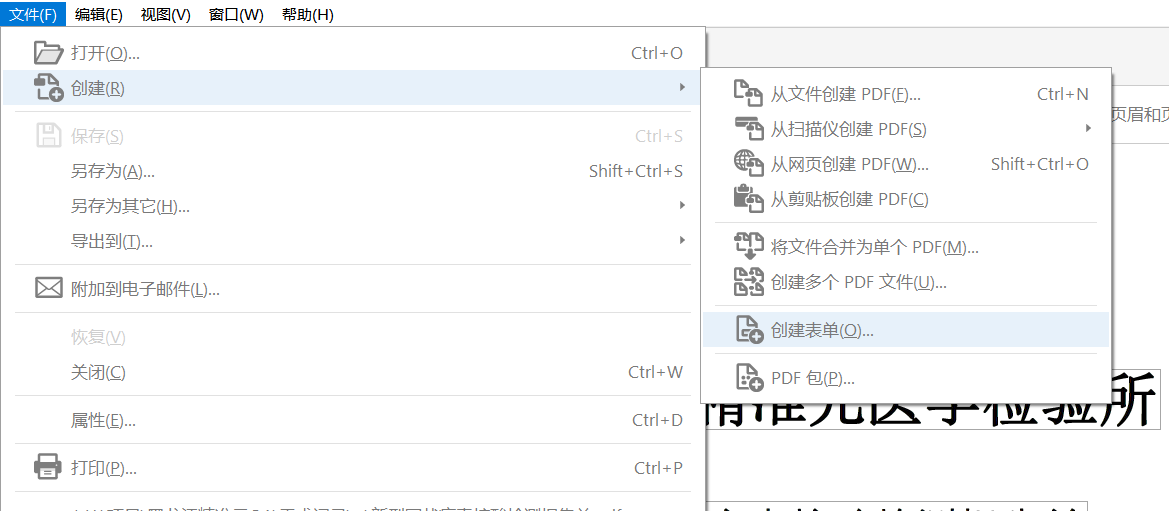
我们安装完Acrobat之后使用鼠标右键PDF模板,选择 使用Acrobat编辑->文件->创建->创建表单
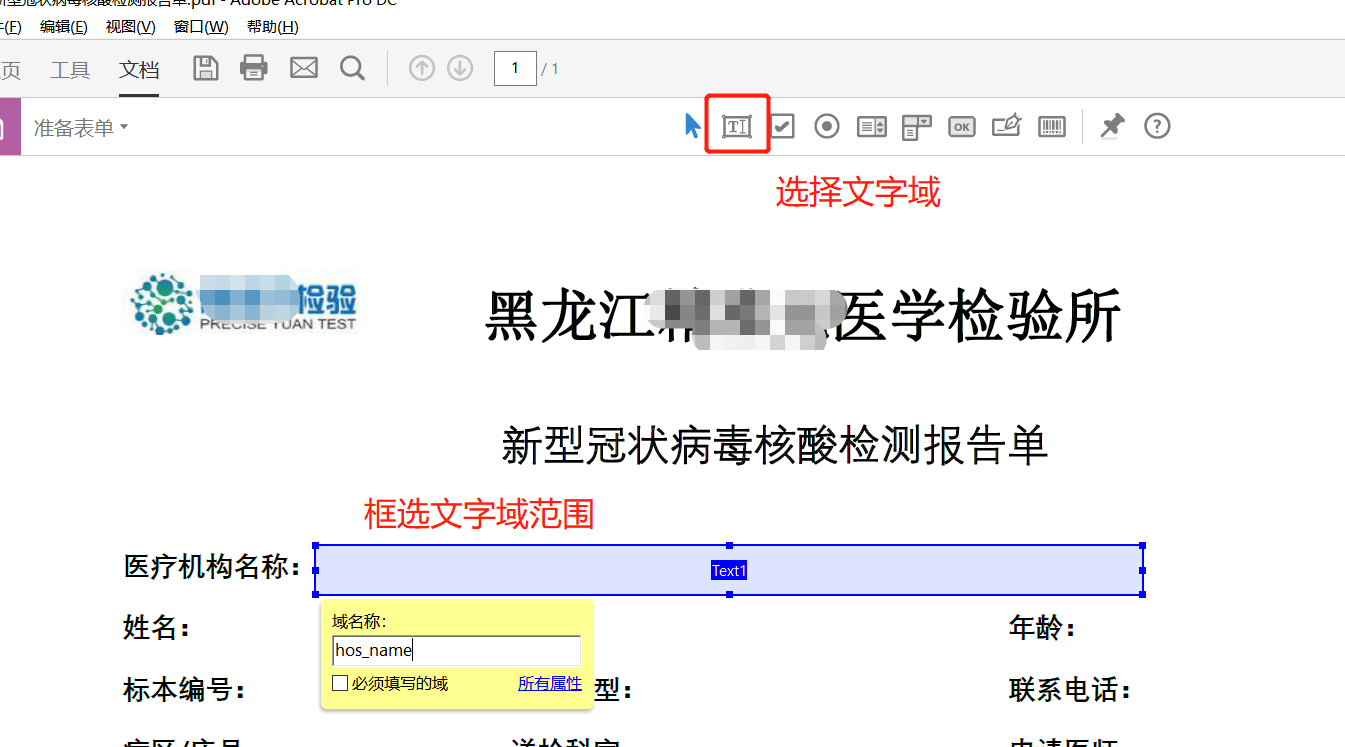
然后选择文字域,即可进行编辑。无论是文字还是图片,都使用文字域进行框选。
<!-- poi的包 -->
<dependency>
<groupId>xml-apis</groupId>
<artifactId>xml-apis</artifactId>
<version>1.4.01</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.15</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>com.deepoove</groupId>
<artifactId>poi-tl</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency> import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import com.itextpdf.text.*;
import com.itextpdf.text.pdf.*;
public class PdfUtils {
// 利用模板生成pdf
public static void pdfout(Map<String,Object> o) {
// 模板路径
String templatePath = "C:/mytest.pdf";
// 生成的新文件路径
String newPDFPath = "C:/testout1.pdf";
PdfReader reader;
FileOutputStream out;
ByteArrayOutputStream bos;
PdfStamper stamper;
try {
BaseFont bf = BaseFont.createFont("c://windows//fonts//simsun.ttc,1" , BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
Font FontChinese = new Font(bf, 5, Font.NORMAL);
out = new FileOutputStream(newPDFPath);// 输出流
reader = new PdfReader(templatePath);// 读取pdf模板
bos = new ByteArrayOutputStream();
stamper = new PdfStamper(reader, bos);
AcroFields form = stamper.getAcroFields();
//文字类的内容处理
Map<String,String> datemap = (Map<String,String>)o.get("datemap");
form.addSubstitutionFont(bf);
for(String key : datemap.keySet()){
String value = datemap.get(key);
form.setField(key,value);
}
//图片类的内容处理
Map<String,String> imgmap = (Map<String,String>)o.get("imgmap");
for(String key : imgmap.keySet()) {
String value = imgmap.get(key);
String imgpath = value;
int pageNo = form.getFieldPositions(key).get(0).page;
Rectangle signRect = form.getFieldPositions(key).get(0).position;
float x = signRect.getLeft();
float y = signRect.getBottom();
//根据路径读取图片
Image image = Image.getInstance(imgpath);
//获取图片页面
PdfContentByte under = stamper.getOverContent(pageNo);
//图片大小自适应
image.scaleToFit(signRect.getWidth(), signRect.getHeight());
//添加图片
image.setAbsolutePosition(x, y);
under.addImage(image);
}
stamper.setFormFlattening(true);// 如果为false,生成的PDF文件可以编辑,如果为true,生成的PDF文件不可以编辑
stamper.close();
Document doc = new Document();
Font font = new Font(bf, 32);
PdfCopy copy = new PdfCopy(doc, out);
doc.open();
PdfImportedPage importPage = copy.getImportedPage(new PdfReader(bos.toByteArray()), 1);
copy.addPage(importPage);
doc.close();
} catch (IOException e) {
System.out.println(e);
} catch (DocumentException e) {
System.out.println(e);
}
}
public static void main(String[] args) {
Map<String,String> map = new HashMap();
map.put("name","张三");
map.put("creatdate","2018年1月1日");
map.put("weather","晴朗");
map.put("sports","打羽毛球");
Map<String,String> map2 = new HashMap();
map2.put("img","c:/50336.jpg");
Map<String,Object> o=new HashMap();
o.put("datemap",map);
o.put("imgmap",map2);
pdfout(o);
}
} 出于浏览器的同源策略限制。同源策略/SOP(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到XSS、CSFR等攻击,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互。所谓同源(即指在同一个域)就是两个页面具有相同的协议(protocol),主机(host)和端口号(port)。当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域跨域并不是请求发不出去,请求能发出去,服务端能收到请求并正常返回结果,只是结果被浏览器拦截了。
在 HTML 中,<a>, <form>, <img>, <script>, <iframe>, <link> 等标签以及 Ajax 都可以指向一个资源地址,而所谓的跨域请求就是指:当前发起请求的域与该请求指向的资源所在的域不同时的请求。
举个例子:假如一个域名为 aaa.cn的网站,它发起一个资源路径为 aaa.cn/books/getBookInfo的 Ajax 请求,那么这个请求是同域的,因为资源路径的协议、域名以及端口号与当前域一致(例子中协议名默认为http,端口号默认为80)。但是,如果发起一个资源路径为 bbb.com/pay/purchase的 Ajax 请求,因为请求域 http://bbb.com:80和发起请求的域 http://aaa.cn:80不同,那么这个请求就是跨域请求。
跨源资源共享 Cross-Origin Resource Sharing (CORS)(或通俗地译为跨域资源共享)是一种机制,该机制使用附加的 HTTP 头来告诉浏览器,准许运行在一个源上的Web应用访问位于另一不同源选定的资源。 当一个Web应用发起一个与自身所在源(域,协议和端口)不同的HTTP请求时,它发起的即跨源HTTP请求。
出于安全性,浏览器限制脚本内发起的跨源HTTP请求。 例如,XMLHttpRequest和Fetch API遵循同源策略。 这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非响应报文包含了正确CORS响应头。
跨源域资源共享( CORS )机制允许 Web 应用服务器进行跨源访问控制,从而使跨源数据传输得以安全进行。现代浏览器支持在 API 容器中(例如 XMLHttpRequest 或 Fetch )使用 CORS,以降低跨源 HTTP 请求所带来的风险。
跨源资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站通过浏览器有权限访问哪些资源。另外,规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨源请求。服务器确认允许之后,才发起实际的 HTTP 请求。在预检请求的返回中,服务器端也可以通知客户端,是否需要携带身份凭证(包括 Cookies 和 HTTP 认证相关数据)。
CORS请求失败会产生错误,但是为了安全,在JavaScript代码层面是无法获知到底具体是哪里出了问题。你只能查看浏览器的控制台以得知具体是哪里出现了错误。
关于CORS的具体介绍,我在这里不详细展开了,有兴趣的可以查看CORS文档:
package com.jzyoa.filter;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class CrossFilter implements Filter{
private boolean isCross = false;
@Override
public void destroy() {
isCross = false;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain)
throws IOException, ServletException {
if (isCross) {
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
HttpServletResponse httpServletResponse = (HttpServletResponse) response;
System.out.println("拦截请求: " + httpServletRequest.getServletPath());
// 允许所有源的访问。
httpServletResponse.setHeader("Access-Control-Allow-Origin", "*");
httpServletResponse.setHeader("Access-Control-Allow-Methods", "POST, GET, OPTIONS, DELETE");
httpServletResponse.setHeader("Access-Control-Max-Age", "0");
httpServletResponse.setHeader("Access-Control-Allow-Headers",
"Origin, No-Cache, X-Requested-With, If-Modified-Since, Pragma, Last-Modified, Cache-Control, Expires, Content-Type, X-E4M-With,userId,token");
httpServletResponse.setHeader("Access-Control-Allow-Credentials", "true");
httpServletResponse.setHeader("XDomainRequestAllowed", "1");
}
filterChain.doFilter(request, response);
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
String isCrossStr = filterConfig.getInitParameter("IsCross");
isCross = isCrossStr.equals("true") ? true : false;
System.out.println(isCrossStr);
}
} 我的项目比较老,还使用着web.xml,所以我在web.xml里面配置过滤器。
<filter>
<filter-name>CrossFilter</filter-name>
<filter-class>com.jzyoa.filter.CrossFilter</filter-class>
<init-param>
<param-name>IsCross</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>CrossFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>