This repository has been archived by the owner on Aug 4, 2024. It is now read-only.
SSTable
SSTable(Sorted String Table)作为数据持久化于硬盘之中的主要媒介,涵盖了DB中几乎的数据,是LSM核心组件之一。
SSTable相关组件分为3个部分
- SSTable 本体
- SSTableLoader 加载器
- Block 数据读取单位
SSTable内部结构(主要参考自LevelDB)
- 多个DataBlock(实际数据)
- 单个IndexBlock(二级索引)
- 单个MetabBlock(统计信息)
- 单个Footer(基本信息)
LevelDB SSTable参考
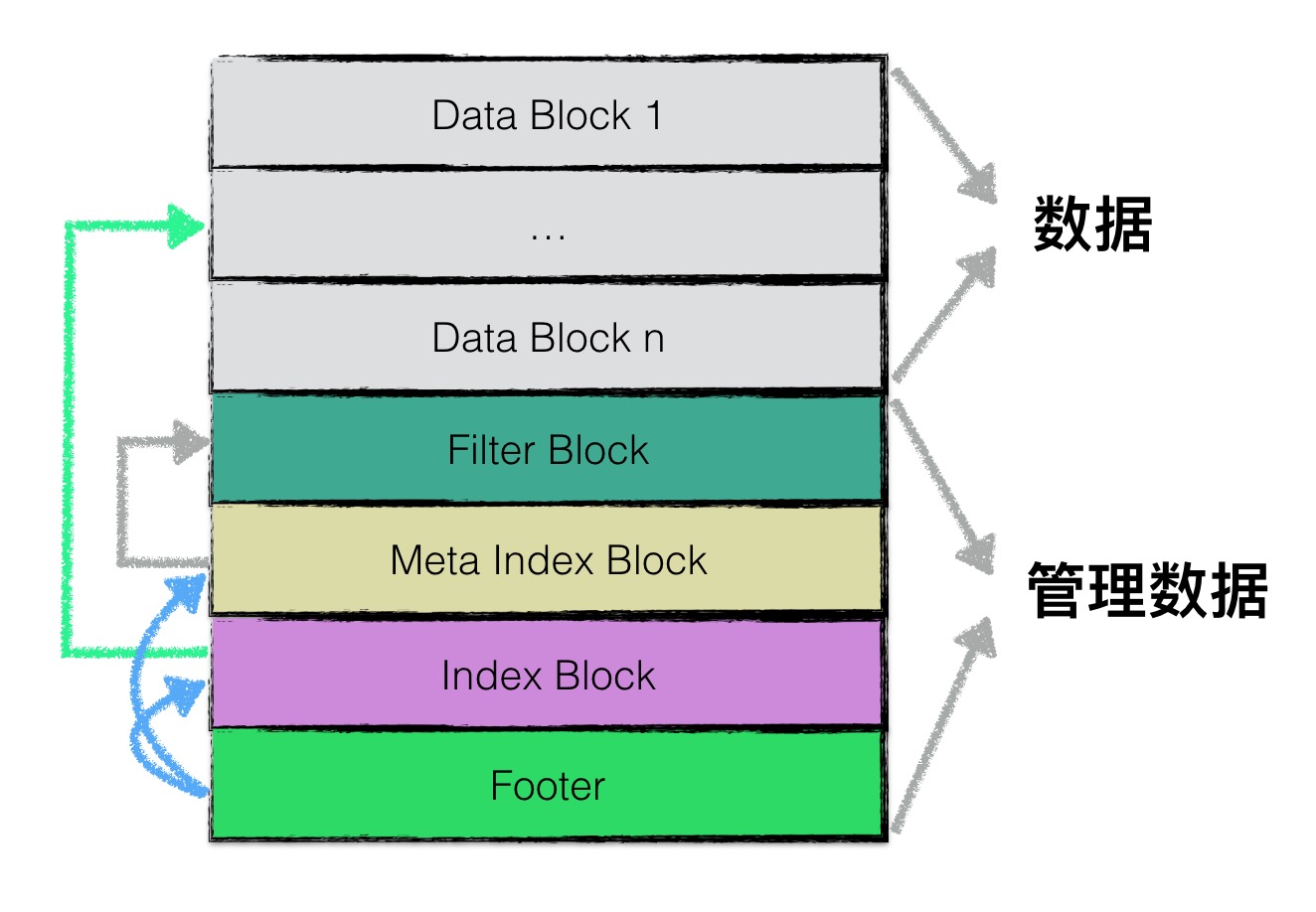
- 尝试从SSTableLoader中获取对应SSTable
- 通过IndexBlock二分查询数据可能存在的DataBlock
- 通过对应的DataBlock再次二分查询查找数据是否存在并返回
Tips: 每个Block的默认大小会控制在4k左右(4k对齐),减少IO次数;IndexBlock使用频率较高,大多数情况下会缓存于BlockCache中,因此大多数情况下读取数据时仅需要读取对应的DataBlock即可
SSTableLoader使用Lazy Load的方式,在使用需要对应SSTable的时候才会加载并缓存到内存之中。
内部基于SharedLruCache(utils/lru)实现,默认使用16个Lru对键值进行hash求余使其实现并行化。
Block是SSTable中存储数据进行读写的最小单位
/// 分为DataBlock和IndexBlock
#[derive(Debug, PartialEq, Eq, Clone)]
pub(crate) struct Block<T> {
restart_interval: usize,
vec_entry: Vec<(usize, Entry<T>)>,
}参考LevelDB的结构图

和LevelDB SSTable Block比较大的差别是,直接使用Config中指定的restart进行读取,因此简化途中下部分restart区域(FIXME: 配置兼容性问题,应当将restart持久化,使Config仅对新Block起作用使其不会导致旧Block读取时产生问题)
Block由若干个Entry顺序组合而成:
pub(crate) struct Entry<T> {
unshared_len: usize,
shared_len: usize,
pub(crate) key: Bytes,
pub(crate) item: T
}Entry之间会以指定的数量进行分组与前缀压缩(DataBlock为16,Index为2,平衡缓存局部性)
- Block进行二分查询时,会判断当前数据是否为restart起始数据
- restart起始数据:直接判断key匹配
- 非restart起始数据:获取该数据往前最接近的restart起始数据,并通过shared_len获取前缀拼接进行匹配