机器学习-周志华_笔记 #24
Comments
|
计科学长吗😂 |
校友!? |
我是南大软院的😂我猜应该是校友吧 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
|
计科学长吗😂 |
校友!? |
我是南大软院的😂我猜应该是校友吧 |
第一章 绪论
机器学习正是这样一门学科,它致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。如果说计算机科学是研究关于
算法的学问,那么可以说机器学习是研究关于学习算法的学问若预测的是离散值,例如好瓜、坏瓜,此类学习任务称为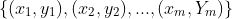 进行学习,建立一个从输入空间
进行学习,建立一个从输入空间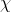 到输出空间
到输出空间 的映射
的映射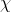 。对二分任务,通常令
。对二分任务,通常令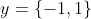 或
或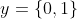 ;对多分类任务,
;对多分类任务,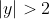 ;对回归任务,
;对回归任务,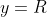 ,R为实数集
,R为实数集
分类;若预测的是连续值,例如西瓜的成熟度0.95、0.37,此类学习任务称为回归。一般地,预测任务是希望通过对训练集根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:监督学习和无监督学习,分类和回归是前者的代表,而聚类则是后者的代表
通常假设样本空间中全体样本服从一个未知的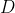 ,我们获得的每个样本都是独立地从这个分布上采样获得的,即
,我们获得的每个样本都是独立地从这个分布上采样获得的,即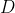 的信息越多,这样就越有可能通过学习获得具有强
的信息越多,这样就越有可能通过学习获得具有强
分布独立同分布。一般而言,训练样本越多,得到的关于第二章 模型评估与选择
通常把分类错误的样本数占样本总数的比例称为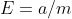
错误率(error rate),即如果在m个样本中有a个样本分类错误,则错误率交叉验证法(cross validation)
调参(parameter tuning)
回归任务最常用的性能度量是
均方误差(mean squared error)查准率(precision)、查全率(recall)与F1
挑出的西瓜中有多少比例是好瓜、所有好瓜中有多少比例被挑了出来
第三章 线性模型
给定由d个属性描述的示例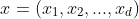 ,
,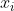
 在
在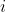 个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即
个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即
如何确定w和b,可试图让均方误差最小化,即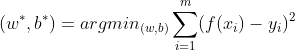
均方误差对应了常用的欧几里得距离或简称欧式距离,基于均方误差最小化来进行模型求解的方法称为
最小二乘法,求解w和b使上式最小化的过程,称为线性回归模型的最小二乘参数估计线性判别分析(Linear Discriminant Analysis,简称LDA),是一种经典的线性学习方法,给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离
第四章 决策树
在对特征排序前先设想一下,对某一个特征进行决策时,我们肯定希望分类后样本的纯度越高越好,也就是说分支结点的样本尽可能属于同一类别。
所以在选择根节点的时候,我们应该选择能够使得“分支结点纯度最高”的那个特征。在处理完根节点后,对于其分支节点,继续套用根节点的思想不断递归,这样就能形成一颗树。
第五章 神经网络
有两种策略用来缓解BP网络的过拟合,第一种策略是早停,另一种策略是正则化
负梯度方向是函数值下降最快的方向,因此梯度下降法就是沿着负梯度方向搜索最优解
第六章 支持向量机
第七章 贝叶斯分类器
贝叶斯定理
极大似然估计,根据实验结果对分布参数作最大概率的估计
第八章 集成学习
通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统
第九章 聚类
K均值聚类
密度聚类DBSCAN
层次聚类,形成树形的聚类结构
第十章 降维与度量学习
k近邻学习
给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个邻居的信息来进行预测
低维嵌入(embedding)
主成分分析(Principal Component Analysis,简称PCA)
The text was updated successfully, but these errors were encountered: