版权 2022 HuggingFace团队。 版权所有。
根据Apache许可证第2版(“许可证”),除非符合许可证的规定,否则你不得使用此文件。 你可以从以下位置获取许可证的副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则根据许可证分发的软件是基于“按原样”无任何担保或条件的基础上分发的,在任何情况下都不对应用程序承担任何担保或条件,无论是明示的还是暗示的。有关许诺的具体语言,请参阅许可证。
YOLOS模型由 Yuxin Fang、Bencheng Liao、Xinggang Wang、Jiemin Fang、Jiyang Qi、Rui Wu、Jianwei Niu、Wenyu Liu 在《You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection》中提出。YOLOS 提议只利用纯粹的 Vision Transformer (ViT) 来进行目标检测,灵感来自于 DETR。结果表明,一个基于编码器的普通 Transformer 模型也可以在 COCO 上实现42 AP,与 DETR 和 Faster R-CNN 等更复杂的模型效果相似。
论文摘要如下:
“Transformer 是否可以从纯粹的序列到序列的角度上进行二维对象和区域级别的识别,并对二维空间结构了解得非常少?为了回答这个问题,我们提出了 You Only Look at One Sequence (YOLOS),这是一系列物体检测模型,基于普通 Vision Transformer 进行开发,只进行了最少的修改、区域先验以及目标任务的归纳偏差。我们发现,对中型 ImageNet-1k 数据集预训练的 YOLOS 模型在具有挑战性的 COCO 物体检测基准上已经达到了相当具有竞争力的性能,例如,BERT-Base 结构直接采用的 YOLOS-Base 可以在 COCO 验证集上获得 42.0 的框的 AP。我们还讨论了当前预训练方案和 Transformer 在视觉中的模型缩放策略对 YOLOS 的影响和限制。”
提示:
- 可以使用 [
YolosImageProcessor] 来为模型准备图像(和可选的目标)。与 DETR 不同,YOLOS 不需要创建pixel_mask。
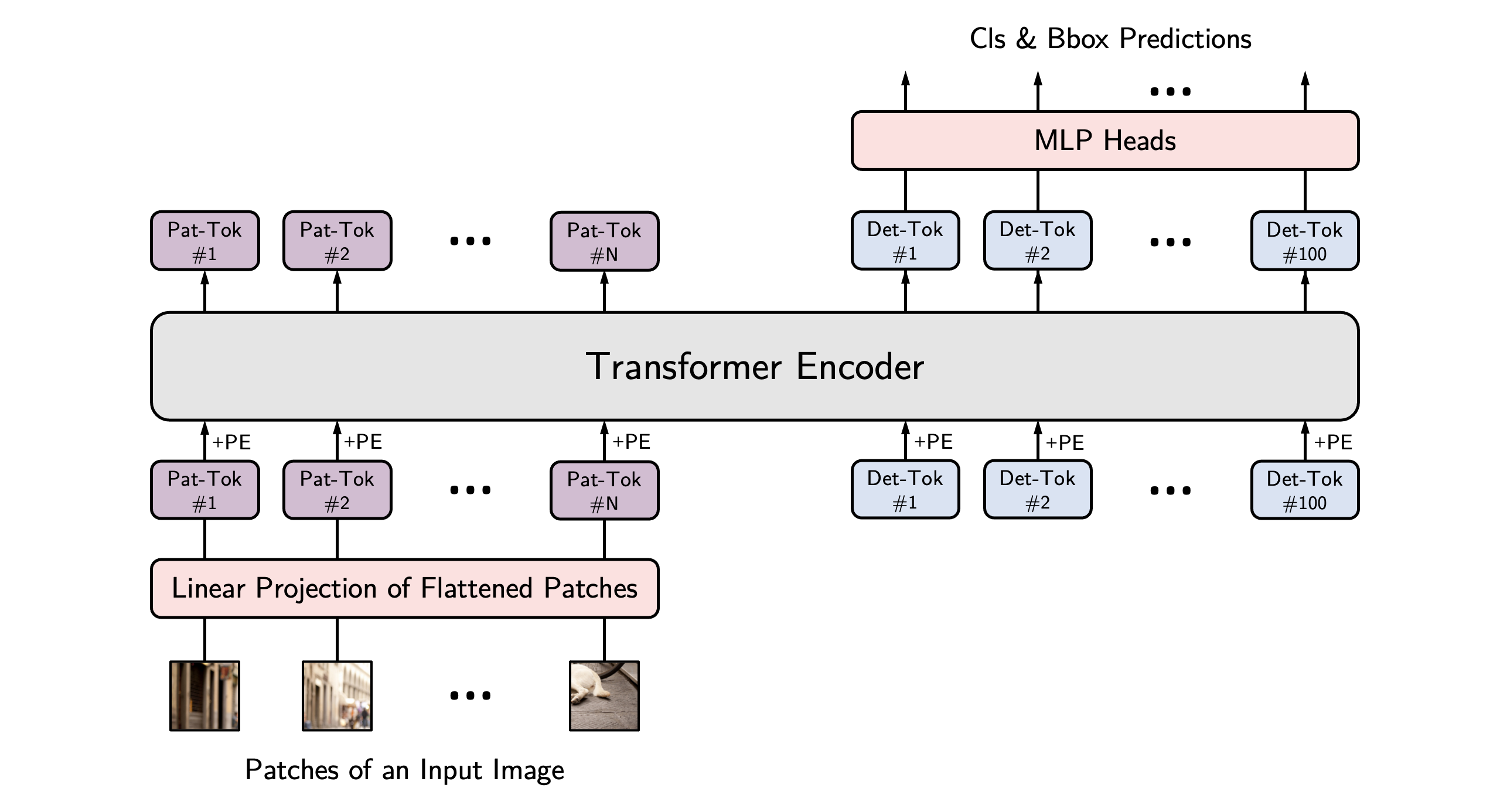
YOLOS 架构。来源于原始论文。
以下是官方 Hugging Face 和社区资源(🌎 表示)的列表,可帮助你开始使用 YOLOS。
- 所有演示推理 + 微调 [
YolosForObjectDetection] 的示例笔记本可以在这里找到。 - 参见:Object detection 任务指南
如果你有兴趣提交要包含在此处的资源,请随时打开 Pull Request,我们将审核它!该资源应该展示一些新的东西,而不是重复现有的资源。
[[autodoc]] YolosConfig
[[autodoc]] YolosImageProcessor - preprocess - pad - post_process_object_detection
[[autodoc]] YolosFeatureExtractor - call - pad - post_process_object_detection
[[autodoc]] YolosModel - forward
[[autodoc]] YolosForObjectDetection - forward