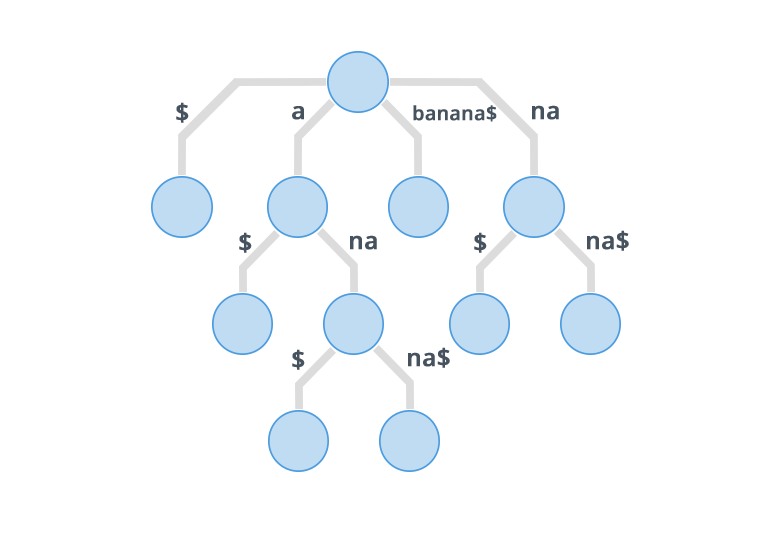
The construction of such a tree for the string {\displaystyle S}S takes time and space linear in the length of S.
Once constructed, several operations can be performed quickly, for instance locating a substring in S,
locating a substring if a certain number of mistakes are allowed etc.
Suffix trees also provide one of the first linear-time solutions for the longest common substring problem.
These speedups come at a cost: storing a string's suffix tree typically requires significantly more space
than storing the string itself.
Building an Suffix Tree is same as building an Trie. We start inserting every character in the string
into the tree. If there's already an Node present, go to that Node. Else, create that Node and go
there. The only difference between a Trie and a Suffix Tree is that in Suffix Tree, we Build a Tree
for all suffixes of the string.
For each Node, we check all of its 26 links (children) and if there's an link present, we go to that
link recursively. The Base case is when there are no children and it is an End of String.
Using Suffix Trees, we can solve problems really faster. There are Applications like:
- Substring or Not. O(m), m = Length of the substring.
- Longest Substring Palindrome. O(n), n = length of the string.
- Longest Common Substring. O(n), n = Length of the string.
- Searching All Patterns. O(z), z = Number of Occurences and m = Length of the Pattern.
- Longest Repeated Substring. O(n), n = Length of the String.