- Language models/ Prompts/ Output parsers
- Chains
- Memory
- Agents
- Callbacks
- Data Augmentation
- Talk to your documents
- RAG evaluation
The core element of any language model application
A prompt refers to the statement or question provided to the LLM to request information.

- Text Prompt Templates
from langchain.prompts import PromptTemplate
template = """You will provided with the sample text. \
Your task is to rewrite the text to be gramatically correct. \
Sample text: ```{sample_text}``` \
Output:
"""
prompt_template = PromptTemplate.from_template(template = template)
sample_text = "Me likes cats not dogs. They jumps high so much!"
final_prompt = prompt_template.format(sample_text = sample_text)
print(final_prompt)
- Chat prompt templates
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
system_template = """You will provided with the sample text. \
Your task is to translate the text into {output_language} language \
and summarize the translated text in at most {max_words} words. \
"""
system_message_prompt_template = SystemMessagePromptTemplate.from_template(system_template)
human_template = "{sample_text}"
human_message_prompt_template = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt_template = ChatPromptTemplate.from_messages([system_message_prompt_template, human_message_prompt_template])
final_prompt = chat_prompt_template.format_prompt(
output_language="English",
max_words=15,
sample_text="Estoy deseando que llegue el fin de semana."
).to_messages()
print(final_prompt)

- LLMs: inputs and outputs text
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(model_name= "gpt-3.5-turbo" , temperature= 0)
tempalte = """You will provided with the sample text. \
Your task is to rewrite the text to be gramatically correct. \
Sample text: ```{sample_text}``` \
Output:
"""
prompt_template = PromptTemplate.from_template(template=template)
sample_text = "Me likes cats not dogs. They jumps high so much!"
final_prompt = prompt_template.format(sample_text=sample_text)
completion = llm(final_prompt)
print(completion)
- Chat models: inputs and outputs chat messages
from langchain.chat_models impots ChatOpenAI
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
chat = ChatOpenAI(temperature=0)
system_template = """You will provided with the sample text. \
Your task is to translate the text into {output_language} language \
and summarize the translated text in at most {max_words} words. \
"""
system_message_prompt_template = SystemMessagePromptTemplate.from_template(system_template)
human_template = "{sample_text}"
human_message_prompt_template = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt_template = ChatPromptTemplate.from_messages([system_message_prompt_template, human_message_prompt_template])
final_prompt = chat_prompt_template.format_prompt(
output_language="English",
max_words=15,
sample_text="Estoy deseando que llegue el fin de semana."
).to_messages()
completion = chat(final_prompt)
print(completion)
Text embedding is used to represent text data in a numerical format that can be understood and processed by ML models.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model = "text-embedding-ada-002")
text = "It is imperative that we work towards sustainable practices, reducing waste and conserving resources."
embedded_text = embeddings.embed_query(text)
print(embedded_text)
Outpus Parsers help get structure responses.
gift_schema = ResponseSchema(
name = "gift",
description="Was the item purchased\
as a gift or somene else?\
Answer True if yes,\
False if not or unknown."
)
delivery_days_schema = ResponseSchema(
name = "delivery_days",
description = "How many days\
did it take for the product\
to arrive? If this \
information is not found,\
output -1."
)
price_value_schema = ResponseSchema(
name="price_value",
description="Extract any\
sentences about the value or \
price, and output them as a \
comma separated Python list."
)
response_schemas = [
gift_schema,
delivery_days_schema,
price_value_schema
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
While using a single LLM may be sufficient for simpler tasks, LangChain provides a standard interface and some commonly used implementations for chaining LLMs together for more complex applications, either among themselves or with other specialized modules. Or you can think simple chain can be defined as sequence of calls.
- LLMChain: Simple chain that consists of PromptTemplate and model
from langchain import PromptTemplate, OpenAI, LLMChain
prompt_template = "What is capital of {country}?"
llm = OpenAI(temperature = 0)
llm_chain = LLMChain(
llm = llm,
prompt = PromptTemplate.from_template(prompt_template)
)
llm_chain("Egypt")
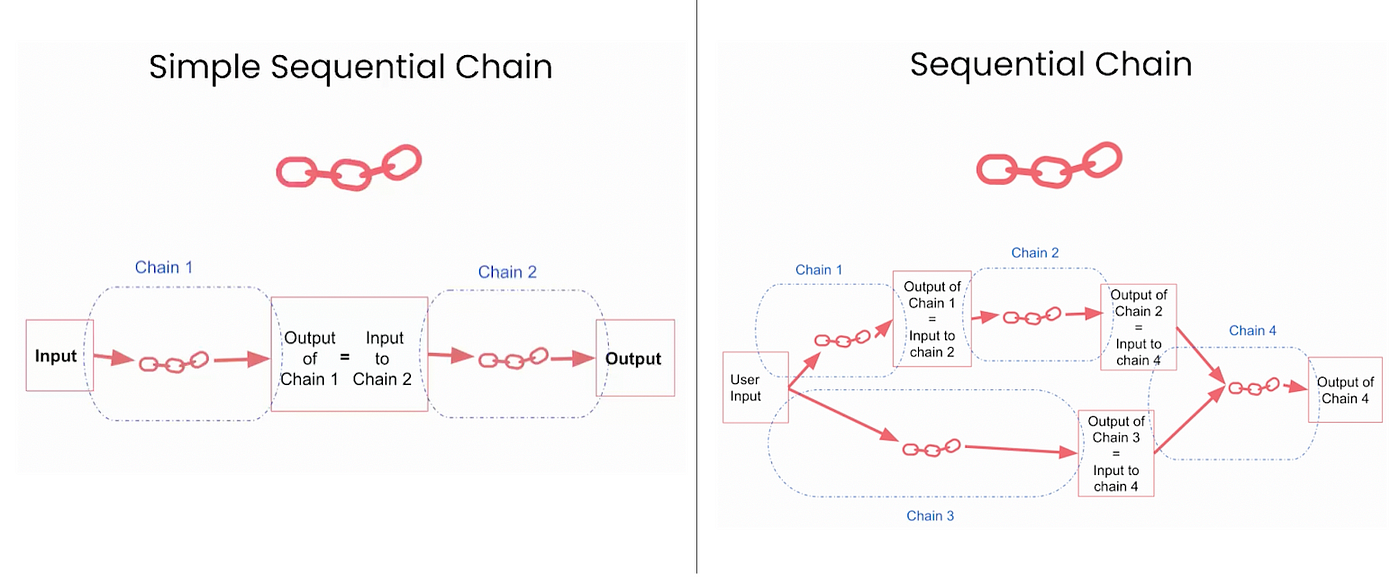
- Sequential Chains: Combine multiple chains where the output of one chain is the input of the next one.
- There are 2 types:
- SimpleSequentialChain: Single input/ output
- SequentialChain: Multiple inputs/ outputs
- There are 2 types:
from langchain.chains import SimpleSequentialChain
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.9)
# Prompt1
first_prompt = ChatPromptTemplate.from_template(
"What is the capital of {country}?"
)
chain_one = LLMChain(llm= llm, prompt = first_prompt)
# prompt2
second_prompt = ChatPromptTemplate.from_template(
"Write a 20 words description for the following \
country: {capital}"
)
chain_two = LLMChain(llm= llm, prompt=second_prompt)
# Simple sequential chain
simple_chain = SimpleSequentialChain(
chains = [chain_one, chain_two],
verbose = True # This line shows the process
)
simple_chain.run("Egypt")
- Router Chain

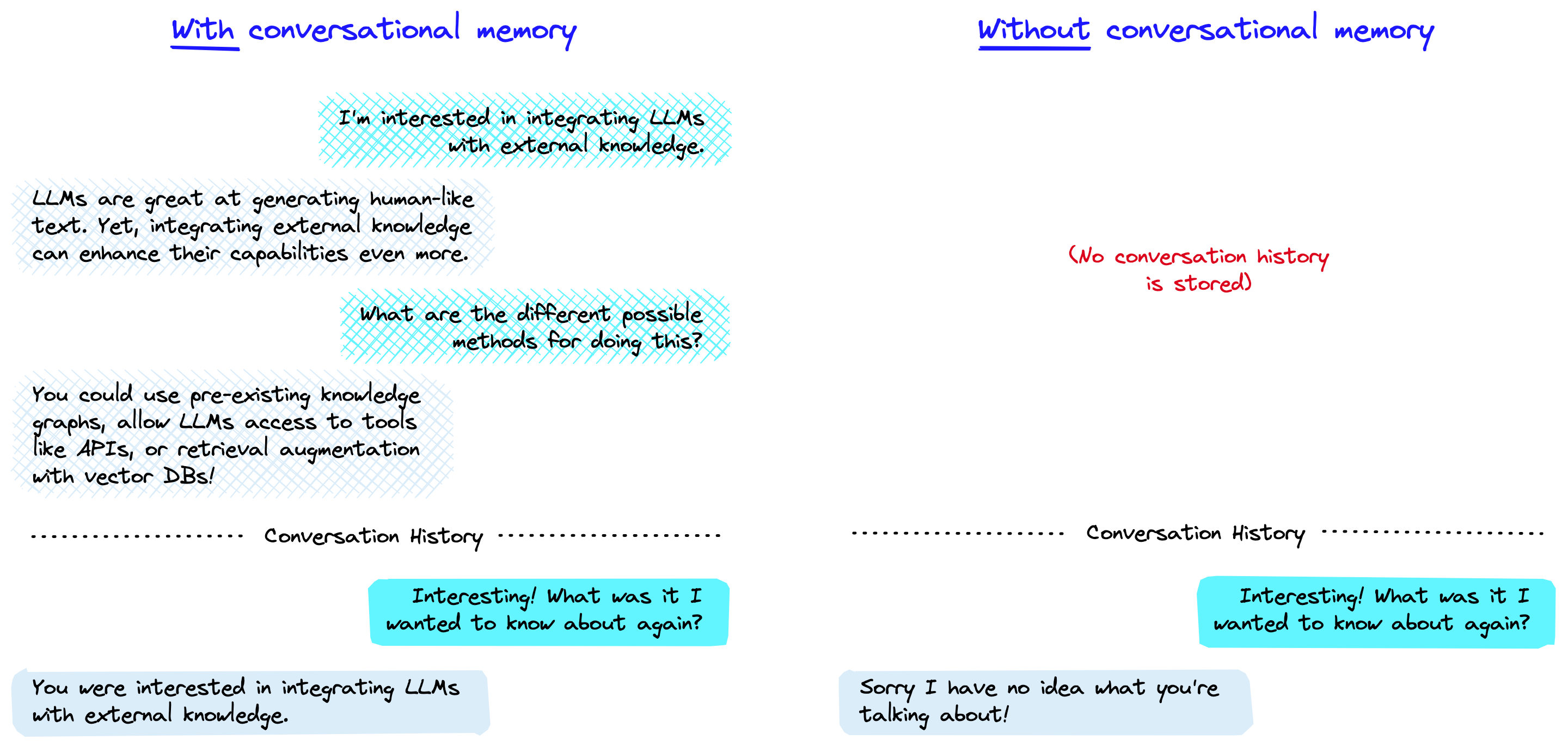
Large Language Models are stateless each transaction is independent.
Chatbots have memory by providing conversation as context. Memory allowas LLM to remember previos interactions with the user
- Memory types
-
ConversationBufferMemory: Allows for storing of messages and then extract the messages in a variable.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory() memory.save_context({"input": "hi"}, {"output": "whats up"}) memory.load_memory_variables({}) -
ConversationBufferWindowMemory: Keeps a list of the interactions of the conversation over time, it only uses the last K interactions.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k = 1) # saves the last message only memory.save_context({"input": "hi"}, {"output": "whats up"}) memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) # it will load the last one as k = 1 -
ConversationTokenBufferMemory: Keeps a buffer of recent interactions in memory, and uses token length rather than number of interactions to determine when to flush interactions.
from langchain.memory import ConversationTokenBufferMemory from langchain.chat_models import ChatOpenAI from langchain.llms import OpenAI llm = ChatOpenAI(temperature=0.0) memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30) memory.save_context({"input": "AI is what?!"}, {"output": "Amazing!"}) memory.save_context({"input": "Backpropagation is what?"}, {"output": "Beautiful!"}) memory.save_context({"input": "Chatbots are what?"}, {"output": "Charming!"}) memory.load_memory_variables({}) -
ConversationSummaryMemory: Creates a summary of the conversation over time.
from langchain.llms import OpenAI from langchain.chains import ConversationChain llm = OpenAI(temperature=0) conversation_with_summary = ConversationChain( llm=llm, memory=ConversationSummaryMemory(llm=OpenAI()), verbose=True ) conversation_with_summary.predict(input="Hi, what's up?") -
ConversationSummaryBufferMemory: Saves the latest X interactions as well as their summary.
from langchain.memory import ConversationSummaryBufferMemory schedule = "Write whatever u want" memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100) memory.save_context({"input": "Hello"}, {"output": "What's up"}) conversation = ConversationChain( llm=llm, memory = memory, verbose=True ) conversation.predict(input="Ask about something in the schedule") -
ConversationEntityMemory: Saves information about entities.
from langchain.memory import ConversationEntityMemory llm = OpenAI(temperature = 0) memory = ConversationEntityMemory(llm = llm) _input = {"input": "Ahmed and Anas are working on Google Brain"} memory.load_memory_variables(_input) memory.save_context( _input, {"output": " That sounds like a great postion! What kind of work ther are doing there?"} ) memory.load_memory_variables({"input": 'who is Ahmed'}) -
VectorStoreRetreiverMemory: Stores interactions in VectorDB and finds the top-K most similar documents every time it is called.
-
We can use multiple memories at the same time.
- Agents make use of a LLM to decide on which Action to take. (Actions are taken by the agent via various tools.)
- After an Action is completed, the Agent enters the Observation step.
- From Observation step Agent shares a Thought; if a final answer is not reached, the Agent cycles back to another Action in order to move closer to a Final Answer.

- Different types of agents
-
ReAct
from langchain.agents import load_tools, initialize_agent, AgentType from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature = 0) tools = load_tools(["wikipedia"], llm= llm) agent = initialize_agent( tools, llm, agent = AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors = True, verbose = True ) question = "Ahmed Zewil is an Egyptian scientist \ and he has won the Nobel Prize in chemistry \ what was the research he got Nobel prize for?" result = agent(question) -
Define your own tool
from langchain.agents import tool @tool def get_name(mail: str) -> str: """You will be given an email address \ return the name of the user. \ and the name of organization.""" return mail.split("@")[0], mail.split("@")[1] tools = [get_name] agent= initialize_agent( tools + [get_name], llm, agent= AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors= True, verbose= True ) result = agent("whats the user name and the domain name of [email protected]?") -
Python Agent
from langchain.agents.agent_toolkits import create_python_agent from langchain.tools.python.tool import PythonREPLTool from langchain.python import PythonREPL agent = create_python_agent( llm, tool = PythonREPLTool(), verbose = True ) student_grades = [["Ahmed", "90"], ["Sam", "92"], ["Aml", "84"], ["Passant", "94"], ["Geoff","80"], ["Madison","88"], ] agent.run( f"""Sort these students by \ their grades from the \ highest to lowest \ then print the output: {student_grades}""" )
-
This code from langchain Modules
from langchain.callbacks import StdOutCallbackHandler
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
handler = StdOutCallbackHandler()
llm = OpenAI()
prompt = PromptTemplate.from_template("1 + {number} = ")
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
chain.run(number=2)
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
chain.run(number=2)
# Callbacks and verbose achieve the same result
Retrieval-augmented generation is a technique used in natural language processing that combines the power of both retrieval-based models and generative models to enhance the quality and relevance of generated text.
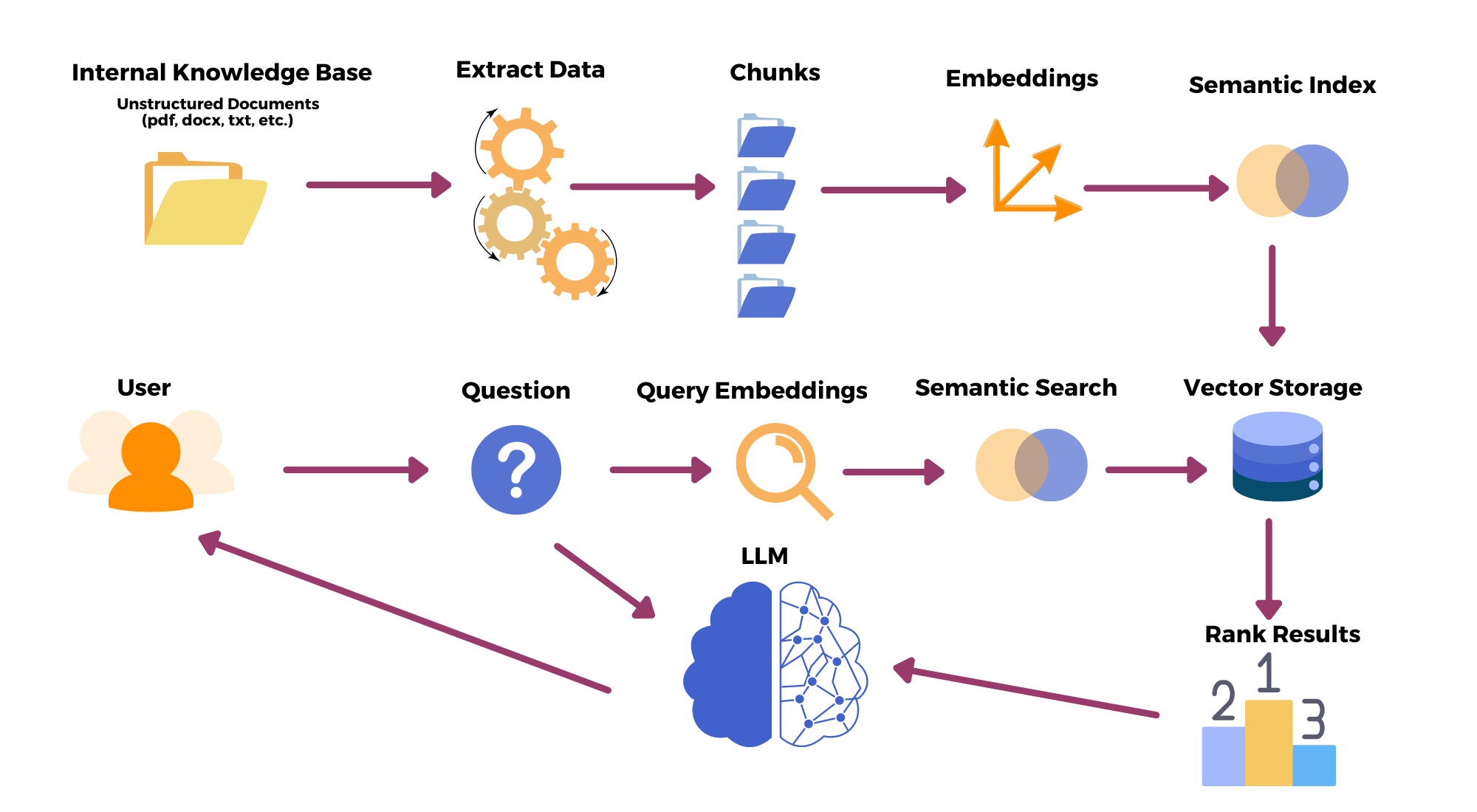
Implementation of Retrieval Augmentation (with langchain/ in general) involves some steps:
-
Document loaders
- Load documents of different sources/formats, Loaders deal with specifics of accessing (Data Bases, Youtube, .....) and converting (PDF, HTML, ....) data.
- Return list of document objects.
from langchain.document_loaders import TextLoader loader = TextLoader("./readme.md") loader.load() -
Creating Chunks
- Splitting the loaded documents into small chunks and add overlap (to retain meaningful relationships).
- Types of splitters:
- CharacterTextSplitter
- MarkdownTextSplitter
- TokenTextSplitter
- SentenceTransformersTextSplitter
- RecursiveCharacterTextSplitter
- Language (cpp, python, ...)
- NLTKTextSplitter
- spacyTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter text_spliter = RecursiveCharacterTextSplitter( chunk_size = 50, chunk_overlap = 10, # Optional length_function = len, add_start_index = True, seperator = "\n\n" # enter whatever seperator u want ) texts = text_splitter.create_documents([Enter your documents]) -
Text Embeddings
- Converting text into vectors, vectors that capture content/meaning.
from langchain.embeddings.openai import OpenAIEmbeddings embedding = OpenAIEmbeddings() sentence = "My name is Ahmed Eldokmak, nice to meet you" embedding.embed_query(sentence) -
Vector Store
- Store embedded data.
from langchain.vectorstores import chromadb db = chromadb.from_documents(documents, embedding) -
Similarity search
- Locks for relevant docs to your question
question = "What is the name of lecturer?" docs = db.similarity_search(question, k=3) # returns 3 relevant docs- Failure cases of similarity search
- It doesn't have diversity, gets duplicate docs. (Solution: MMR)
- Specificity. e.g. you have 4 sections in the docs, and you ask a question about section 1 only, you get answer from all 4 sections. (Solution: metadata)
-
Retrieval
- Accessing the data in the vector store
from langchain.vectorstores import Chroma from langchain.embeddings.openai import OpenAIEmbeddings persist_directory = "/kaggle/working/" embedding = OpenAIEmbeddings() vectordb = Chroma( persist_directory = persist_directory, embedding_function = embedding ) texts = [] question = ""- Basic semantic similarity. Explained.
db.similarity_search(question, k=2) - MMR (Maximum Marginal Relevance): You pick the 'fetch_k' most similar responses, and within these responses you chose the 'k' most diverse.
db.max_marginal_relevance_search(question, fetch_k= 3, k= 2) - Inculding Metadata add filter to the vector database
docs = vectordb.similarity_search( question, k=3, filter={"source":"Enter meta data"} )
- Basic semantic similarity. Explained.
- LLM Aided Retrieval: e.g. SelfQuery where we use LLM to convert the question into query.
- You can find some examples in the notebook 5-Data Augmentation
- Compression: Increase the number of results you can put in the context by shrinking the responses to only the relevant information.
- You can find some examples in the notebook 5-Data Augmentation
- Accessing the data in the vector store
Just wrapping every thing of data augmentation together. You can check the notebook Ask your documents
- Note for chain there are different types:
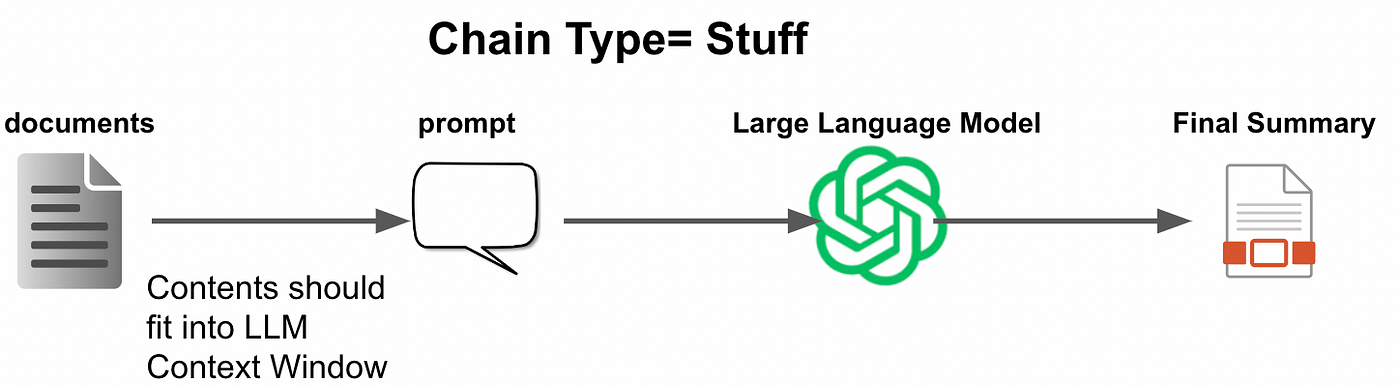
- Stuff method: The diffult which make the full context as prompt in one call.
- Map_reduce: Split the context into multiple chunks pass each chunk to LLM and take all output as input to LLM.
- Refine: Split the context into multiple chunks pass the first one to LLM and its output with the seconde chunk as input to LLm and so on until you reach the final chunk.
- Map_rerank: Split the context into multiple chunks pass each chunk to LLM then select highest score.
- Stuff method: The diffult which make the full context as prompt in one call.

We need RAG models to use the given context to correctly answer a question, generate text, or write summary. This is challenging and difficult to evaluate.
# Load your model
model_name = "meta-llama/Llama-2-13b-chat-hf"
# Load your Evaluator
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "Enter Your API-KEY"
evaluation_llm = ChatOpenAI(model="gpt-4")
question = "How many people are living in Nuremberg?"
context="Nuremberg is the second-largest city of the German state of Bavaria after its capital Munich, and its 541,000 inhabitants make it the 14th-largest city in Germany. On the Pegnitz River (from its confluence with the Rednitz in Fürth onwards: Regnitz, a tributary of the River Main) and the Rhine–Main–Danube Canal, it lies in the Bavarian administrative region of Middle Franconia, and is the largest city and the unofficial capital of Franconia. Nuremberg forms with the neighbouring cities of Fürth, Erlangen and Schwabach a continuous conurbation with a total population of 812,248 (2022), which is the heart of the urban area region with around 1.4 million inhabitants,[4] while the larger Nuremberg Metropolitan Region has approximately 3.6 million inhabitants. The city lies about 170 kilometres (110 mi) north of Munich. It is the largest city in the East Franconian dialect area."
prompt = f"""Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}"""
pred = generate(prompt)
print(pred)
# 'According to the text, Nuremberg has a population of 541,000 inhabitants.'
false_pred = generate(question)
print(false_pred)
# As of December 31, 2020, the population of Nuremberg, Germany is approximately 516,000 people.
from langchain.evaluation import load_evaluator
from pprint import pprint as print
evaluator = load_evaluator("context_qa", llm=evaluation_llm)
eval_result = evaluator.evaluate_strings(
input=question,
prediction=pred,
context=context,
reference="541,000"
)
print(eval_result)
# {'reasoning': 'CORRECT', 'score': 1, 'value': 'CORRECT'}
eval_result = evaluator.evaluate_strings(
input=question,
prediction=false_pred,
context=context,
reference="541,000"
)
print(eval_result)
# {'reasoning': 'INCORRECT', 'score': 0, 'value': 'INCORRECT'}