We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
推荐系统中的召回层主要是希望从全库去捞一批“尽可能好”的物料。“尽可能好”的定义是比较模糊的,可能有多方面的考虑,比如相关性,成交率和点击率等不同目标。如果只用一路召回,很难达到多个目标之间的平衡。最简单的方法就是采用多路召回的方式,去建模不同的目标,相互补充。此外,对某一路而言,建模方式和对象本身就限制了这一路的效果,比如U2I、I2I、U2U2I各自有不同的建模方式和对象,因此也需要相互补充。
然而多路之间由于目标相似也会存在相互竞争的问题,多路之间的重合度过高,召回quota浪费会比较严重。同时,一味地增加新的召回通路,尽管可能会补充一些之前没召回的物料,但是由于资源问题,ROI是很低的,存在边际递减效应。因此,我们需要适时去重新review现有的召回路,对召回路进行合并,比如U2I召回应该如何迭代,才能覆盖其他召回路召回的物料。合并带来的效果并不是说一定是有损或者持平的,在一路召回中联合建模不同对象或许也能实现不同对象之间的交互和关联,从而带来增量。因此,这篇文章主要研究了怎么去联合建模user-item、item-item,user-user之间的关系,并隐式实现了u2u2i、u2i2i等二跳关联。
这类联合建模核心关注有三点:
对于第一点,做法有很多,这篇文章核心是用数据增强去构建了用户和物料的增强视图,然后u2u,i2i,u2i三者分别做对比学习,从而来捕捉不同对象之间的关联。
对于第二点来说,就得看自己公司的结构是否支持这种多跳召回。对于u2u2i的话,u2u的部分可以用离线产出的索引来检索,u2i部分可以是离线索引的方式,也可以是ANN检索的方式。如果是ANN检索,问题主要是一个user拉了N个user,然后发起了N次ANN召回,负载比较高。对于u2i2i的话,u2i和i2i部分怎么去做也需要去思考。痛点就是实时性和系统负载的平衡。
对于第三点来说,一个模型实现了多路召回,返回的doc肯定还是需要一个统一的rerank方式去打分截断,怎么根据业务去定义这种rerank方式也是需要考虑的。
文章把该问题建模成一个topN推荐问题,U就是用户集合,V是物料集合,X是用户的历史行为序列。$e_u$和$e_v$分别就是用户表征和物料表征。预估的商品被推荐的概率是三个概率的线性加权,权重比经过网格搜索是1:1:1。三个概率分别表示:u2i,u2u和i2i。
从这张图就知道,用的还是老生常谈的对比学习技术,其核心就是用什么增强方式构建正负样本。
一个mini batch(N个)的(user, item)pair对,每个pair对包括:用户的id特征、用户画像特征、用户历史交互的物料id序列;物料id、物料基础特征、物料历史被交互的用户id序列。
除了训练集本身的正负例,还采用了其他正负例构建方式来扩充训练集
随机sample N个(user, item)pair对,针对user和item构造增强view,增强方式一个是field mask,也就是随机mask掉用户和物料的若干特征,例如id,age,category,行为序列中的id等。另一个是对输入embedding进行dropout。对于一个(user, item) pair对,利用这两个增强方式,可以分别形成用户侧的增强正样本和物料侧的增强正样本。由此,一个训练样本变成四元组:$(u,\widetilde{u}, v,\widetilde{v})$。
然后就是经典的对比学习loss,分别针对u2i、u2u和i2i:
最后是针对训练集正负例的bce loss:
最终loss是:
值得注意的是这套框架可以应用到现有任何召回模型上。
腾讯新闻的视频推荐召回上部署了这个方法。训练好这个联合建模的模型(小时级训练)以后,
离线构建u2u和i2i正排,以及ANN索引:
在线Serving:
The text was updated successfully, but these errors were encountered:
No branches or pull requests
CIKM'22 腾讯 | 召回模型大一统:U2I/U2U/I2I召回联合建模
多路召回联合建模问题
推荐系统中的召回层主要是希望从全库去捞一批“尽可能好”的物料。“尽可能好”的定义是比较模糊的,可能有多方面的考虑,比如相关性,成交率和点击率等不同目标。如果只用一路召回,很难达到多个目标之间的平衡。最简单的方法就是采用多路召回的方式,去建模不同的目标,相互补充。此外,对某一路而言,建模方式和对象本身就限制了这一路的效果,比如U2I、I2I、U2U2I各自有不同的建模方式和对象,因此也需要相互补充。
然而多路之间由于目标相似也会存在相互竞争的问题,多路之间的重合度过高,召回quota浪费会比较严重。同时,一味地增加新的召回通路,尽管可能会补充一些之前没召回的物料,但是由于资源问题,ROI是很低的,存在边际递减效应。因此,我们需要适时去重新review现有的召回路,对召回路进行合并,比如U2I召回应该如何迭代,才能覆盖其他召回路召回的物料。合并带来的效果并不是说一定是有损或者持平的,在一路召回中联合建模不同对象或许也能实现不同对象之间的交互和关联,从而带来增量。因此,这篇文章主要研究了怎么去联合建模user-item、item-item,user-user之间的关系,并隐式实现了u2u2i、u2i2i等二跳关联。
大概的解决思路
这类联合建模核心关注有三点:
对于第一点,做法有很多,这篇文章核心是用数据增强去构建了用户和物料的增强视图,然后u2u,i2i,u2i三者分别做对比学习,从而来捕捉不同对象之间的关联。
对于第二点来说,就得看自己公司的结构是否支持这种多跳召回。对于u2u2i的话,u2u的部分可以用离线产出的索引来检索,u2i部分可以是离线索引的方式,也可以是ANN检索的方式。如果是ANN检索,问题主要是一个user拉了N个user,然后发起了N次ANN召回,负载比较高。对于u2i2i的话,u2i和i2i部分怎么去做也需要去思考。痛点就是实时性和系统负载的平衡。
对于第三点来说,一个模型实现了多路召回,返回的doc肯定还是需要一个统一的rerank方式去打分截断,怎么根据业务去定义这种rerank方式也是需要考虑的。
问题建模
文章把该问题建模成一个topN推荐问题,U就是用户集合,V是物料集合,X是用户的历史行为序列。$e_u$和$e_v$分别就是用户表征和物料表征。预估的商品被推荐的概率是三个概率的线性加权,权重比经过网格搜索是1:1:1。三个概率分别表示:u2i,u2u和i2i。
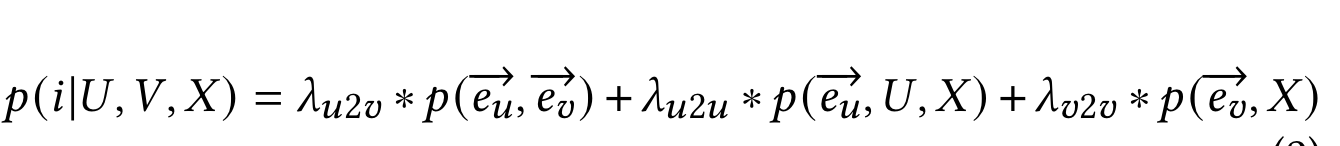
模型和训练
从这张图就知道,用的还是老生常谈的对比学习技术,其核心就是用什么增强方式构建正负样本。
模型输入
一个mini batch(N个)的(user, item)pair对,每个pair对包括:用户的id特征、用户画像特征、用户历史交互的物料id序列;物料id、物料基础特征、物料历史被交互的用户id序列。
高质量正负例构建
除了训练集本身的正负例,还采用了其他正负例构建方式来扩充训练集
loss构建
随机sample N个(user, item)pair对,针对user和item构造增强view,增强方式一个是field mask,也就是随机mask掉用户和物料的若干特征,例如id,age,category,行为序列中的id等。另一个是对输入embedding进行dropout。对于一个(user, item) pair对,利用这两个增强方式,可以分别形成用户侧的增强正样本和物料侧的增强正样本。由此,一个训练样本变成四元组:$(u,\widetilde{u}, v,\widetilde{v})$。
然后就是经典的对比学习loss,分别针对u2i、u2u和i2i:
最后是针对训练集正负例的bce loss:
最终loss是:
值得注意的是这套框架可以应用到现有任何召回模型上。
部署和推理过程
腾讯新闻的视频推荐召回上部署了这个方法。训练好这个联合建模的模型(小时级训练)以后,
离线构建u2u和i2i正排,以及ANN索引:
在线Serving:
效果
The text was updated successfully, but these errors were encountered: